Answer the question
In order to leave comments, you need to log in
Why doesn't undersampling work for decision trees?
I experimented with sampling by fraud from here .
The sample consists of 284807 transactions, of which 497 are of one class, the rest are of another class. That is, the ratio is 0.172%.
On the face of the task on unbalanced classes, I wanted to check how simple random undersampling works. I split the sample into 20 parts, and checked through the area under the precision-recall curve.
I started with linear regression, everything is obvious here (undersampling helps, but at about half of the thrown out we get the optimal result both for precision and for recall): 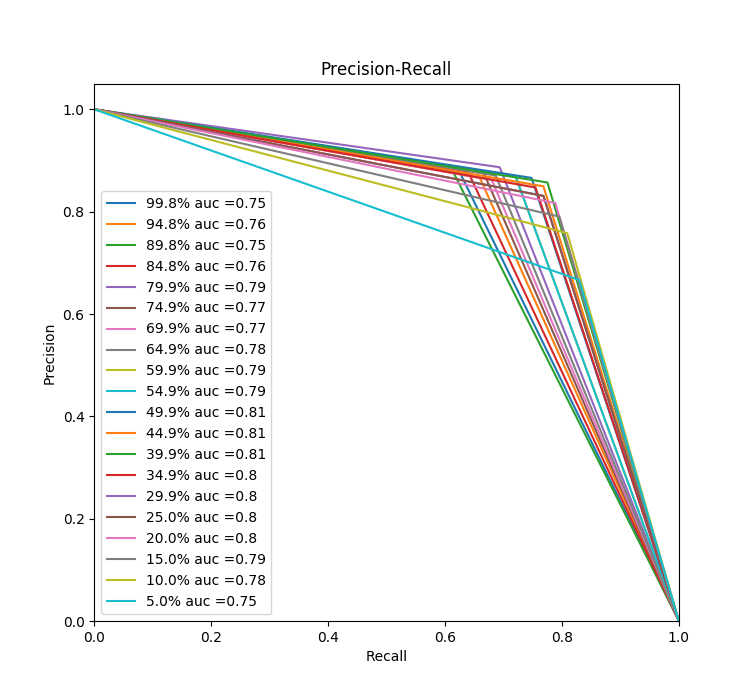
A rather strange situation with decision trees: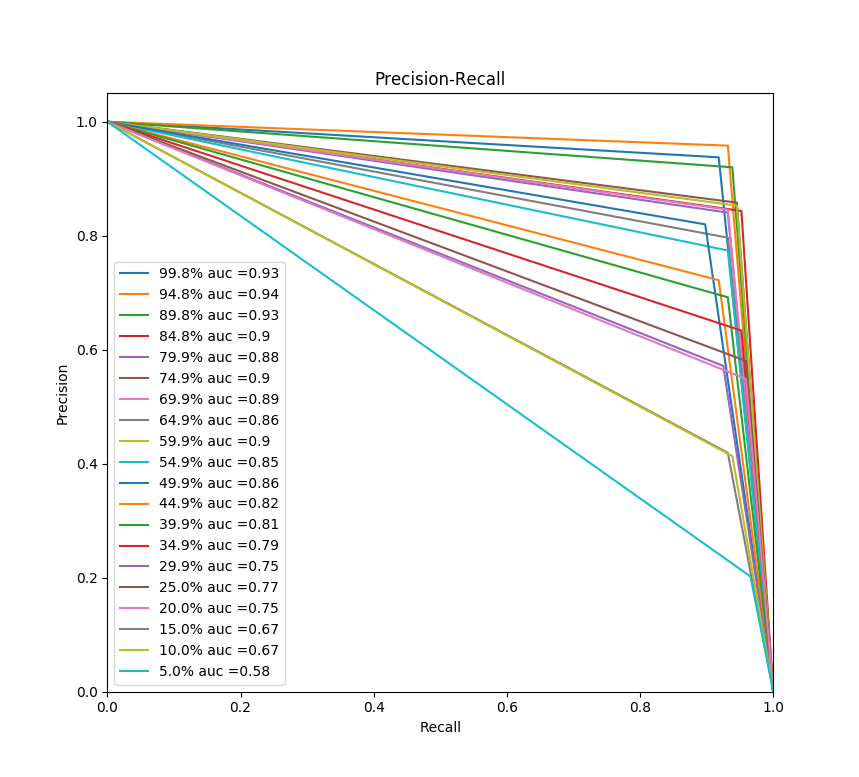
There is a feeling as if the trees do an excellent job with unbalanced classes (from the threshold we get an excellent recall). Moreover, if you don’t touch the sample, then the indicators are bad, but if you randomly take at least 1 transaction less from the sample, the metrics jump. Why is this happening?
Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question