Answer the question
In order to leave comments, you need to log in
What is my database schema design mistake?
There is a preliminary schema of the database (section of the schema): 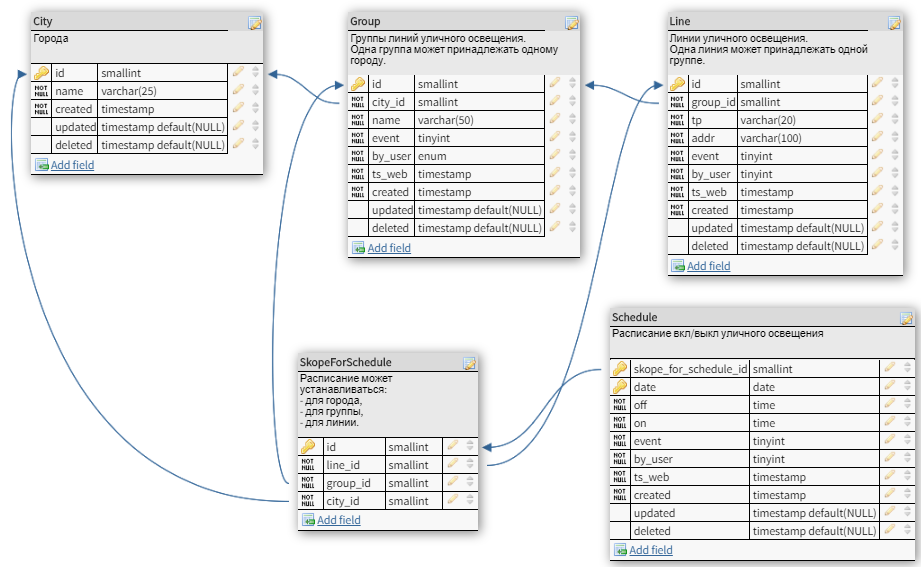
A brief description of the subject area: There is a Schedule
table , in which power engineers (users) in different cities set a schedule for turning on and off street lighting (via the web-face, of course).
Users can create a schedule for the whole city, as well as for groups of lighting lines, and even for individual lines. Therefore, the Schedule table is referenced by FK to the "scope" for the established schedule. The schedule set for a line has priority over the schedule set for the group to which this line belongs (a line can only belong to one group at a particular time).
Groups and cities are in the same relation.
I don't like the SkopeForSchedule label . I don't like the fact that one "scope" for the schedule can be done in several ways. For example, the entries (line_id = 1, group_id = 1, city_id = 1), (line_id = 1, group_id = 2, city_id = 1) and (line_id = 1, group_id = 10, city_id = 111) represent the same "scope" – line_id = 1. I remind you that the value in line_id takes precedence over the value in group_id, and the value in group_id takes precedence over the value in city_id.
The second thing I don't like about this scheme. Users can create and delete cities, groups and lines. In this case, when a user deletes, for example, a group, the corresponding entry in the Group table is not deleted, but is marked with the time of deletion in the deleted field. It may turn out that at first some line belonged to one group, and then began to belong to another group. That is, in the historical context, the Group and Line tables are related as M:N. The City and Group tables are similarly related . Therefore, M:N labels must be added for these two links.
How good is such a scheme in general and what should be done with the ScopeForSchedule table in the end ?
Answer the question
In order to leave comments, you need to log in
Bad scheme. It will work, but not transparently.
The problem table tries to solve the business logic. The solution is to make three many-to-many relationship tables, and move the aggregation to the application
Taking into account the questions about the changelog, I propose a scheme:
City: code, name.
Group: code, city code, name.
Line, code, group code, name.
Schedule: code, line code, date, etc.
Schedule archive: city name, group name, line name, user name, validity time, action (created, modified, deleted) (city, group, line, schedule), schedule data . You can add the corresponding code to the names for reference, without a foreign key.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question