Answer the question
In order to leave comments, you need to log in
Python. Parsing problem. What is the problem?
Strange situation with BeautifulSoup
I'm trying to find tags using the finaAll() method, but I'm getting the following situations:
import requests
from bs4 import BeautifulSoup
class Parse:
def __init__(self, url):
self.link = url
self.html = Parse.__get_html(self.link) # получаем html-страницу
def __get_html(link):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
req = requests.get(link, headers = headers)
return req.text
# Следующие методы ищут в собранной html-странице теги, содержащие называния, цены и даты, а затем собирают
# их в список и возвращают этот список
def get_title(self):
html = self.html
soup = BeautifulSoup(html, 'html.parser')
titles_tags = soup.findAll('div', class_ = 'snippet-title-row')
titles = []
for i in titles_tags:
text = str(i)
get_title = text.split('>')[4].split('<')[0].split('\n')[1]
titles.append(get_title)
return titles
def get_price(self):
html = self.html
soup = BeautifulSoup(html, 'html.parser')
price_tags = soup.findAll('span', class_ = 'price-text-1HrJ_ text-text-1PdBw text-size-s-1PUdo')
prices = []
for i in price_tags:
text = str(i)
get_price = text.split('>')[1].split('<')[0]
prices.append(get_price)
return prices
def get_data(self):
html = self.html
soup = BeautifulSoup(html, 'html.parser')
data_tags = soup.findAll('div', class_ = 'date-text-2jSvU text-text-1PdBw text-size-s-1PUdo text-color-noaccent-bzEdI')
datas = []
for i in data_tags:
text = str(i)
get_data = text.split('>')[1].split('<')[0]
datas.append(get_data)
return datas
# Здесь мы реализовываем методы
class Interface(Parse):
def __init__(self, url):
parse = Parse(url) # Создаем экземпляр класса, даем ссылку на страницу и получаем html-страницу
self.title = parse.get_title() # Получаем список, содержащий название
self.prices = parse.get_price() # Получаем список, содержащий цены
self.data = parse.get_data() # Получаем список, содержащий даты
print(self.title)
print(self.prices)
print(self.data)
Interface('https://www.avito.ru/pskov/tovary_dlya_kompyutera?q=i+7+7700')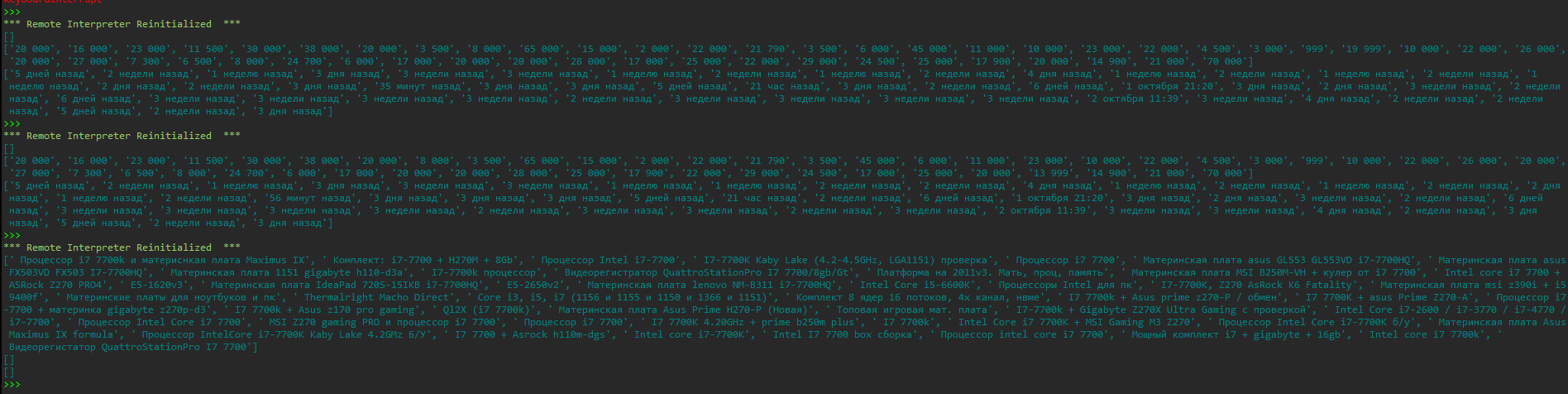
Answer the question
In order to leave comments, you need to log in
Random class endings hint at the fact that they are dynamically generated and do not always exist in the code. Use regular expressions if you want to search by class anyway
But I would do this
import requests
from bs4 import BeautifulSoup
url = 'https://www.avito.ru/pskov/tovary_dlya_kompyutera?q=i+7+7700'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
items = soup.find_all('div', {'class': 'item_table-wrapper'})
parsed_items = []
for item in items:
parsed_items.append({'name': item.find('span', {'itemprop': 'name'}).get_text().strip(),
'price': item.find('meta', {'itemprop': 'price'})['content'],
'date': item.find('div', {'class': 'snippet-date-info'})['data-tooltip']
})
print(parsed_items)Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question