Answer the question
In order to leave comments, you need to log in
How to clear duplicate row values within the same column values in Excel?
There is an unloading of data on orders, where the first column is the order number. Due to the fact that there are several products in one order, there are several lines for each order. The problem is that the costs for the entire order (packaging, shipping cost, etc.) are displayed on each line. It turns out that the costs are duplicated within the order.
Task: within the rows, with a repeated value of the first column, delete the values of all rows in all columns, except for the first such row and the first column of all rows. What functions can achieve this? I will never figure it out.
For example: at the top is the starting table, at the bottom is the required result.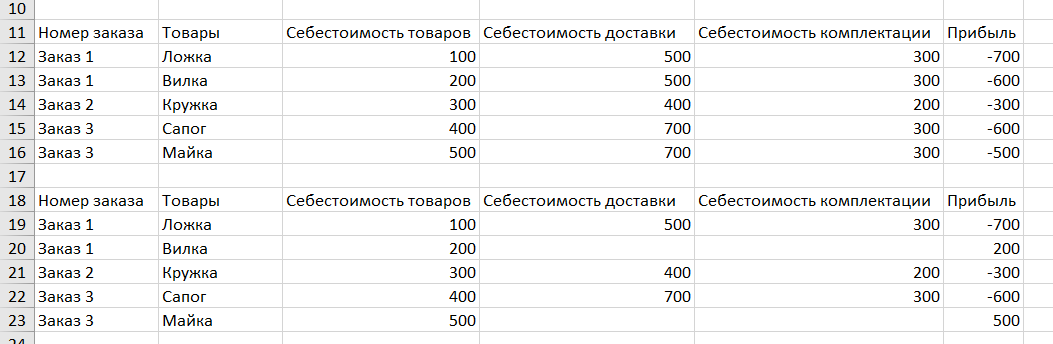
Answer the question
In order to leave comments, you need to log in
As usual - it was worth asking and the solution was found.
1. We number the unique numbers according to the column I need with the function =IF(COUNTIF(B$1:B2;B2)=1;MAX(A$1:A1)+1;"") - see Method 3 here https://www.planetaexcel .ru/techniques/14/103/
2. For each column that needs to be checked (deleted/left), we create a neighboring one, in which we check with a simple formula IF - if there is no number, then it is not unique and there is no need to display the value.
=IF(A2<>A1;D2;"")
What is the logic, you need to sort by order number, and then check in the cost column, according to the order number column, above it (the previous one) has the same number. If the same, then there should not be a number, if different, then the order is new.
You can check through the index and the current line, but it's a little more complicated and longer.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question