Answer the question
In order to leave comments, you need to log in
Why is the date not parsed from the page?
Good afternoon everyone. I am writing a Python parser that parses this page https://www.flashscore.ru/match/6PN2l3Bc/#match-summary
(namely, the time, in the upper right corner), but for some reason it displays None when it starts. Why is this happening? Maybe because the code from the page opens in a separate window? PS If you press ctrl + shift + c, a new window will open for some reason. How to parse time from this page? https://www.flashscore.ru/match/6PN2l3Bc/#match-summary
Code:
from selenium import webdriver
from bs4 import BeautifulSoup
def main():
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.get('https://www.flashscore.ru/match/6PN2l3Bc/#match-summary')
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
time = soup.find('div', class_="description__time mstat-date")
print(time)
if __name__ == '__main__':
main()None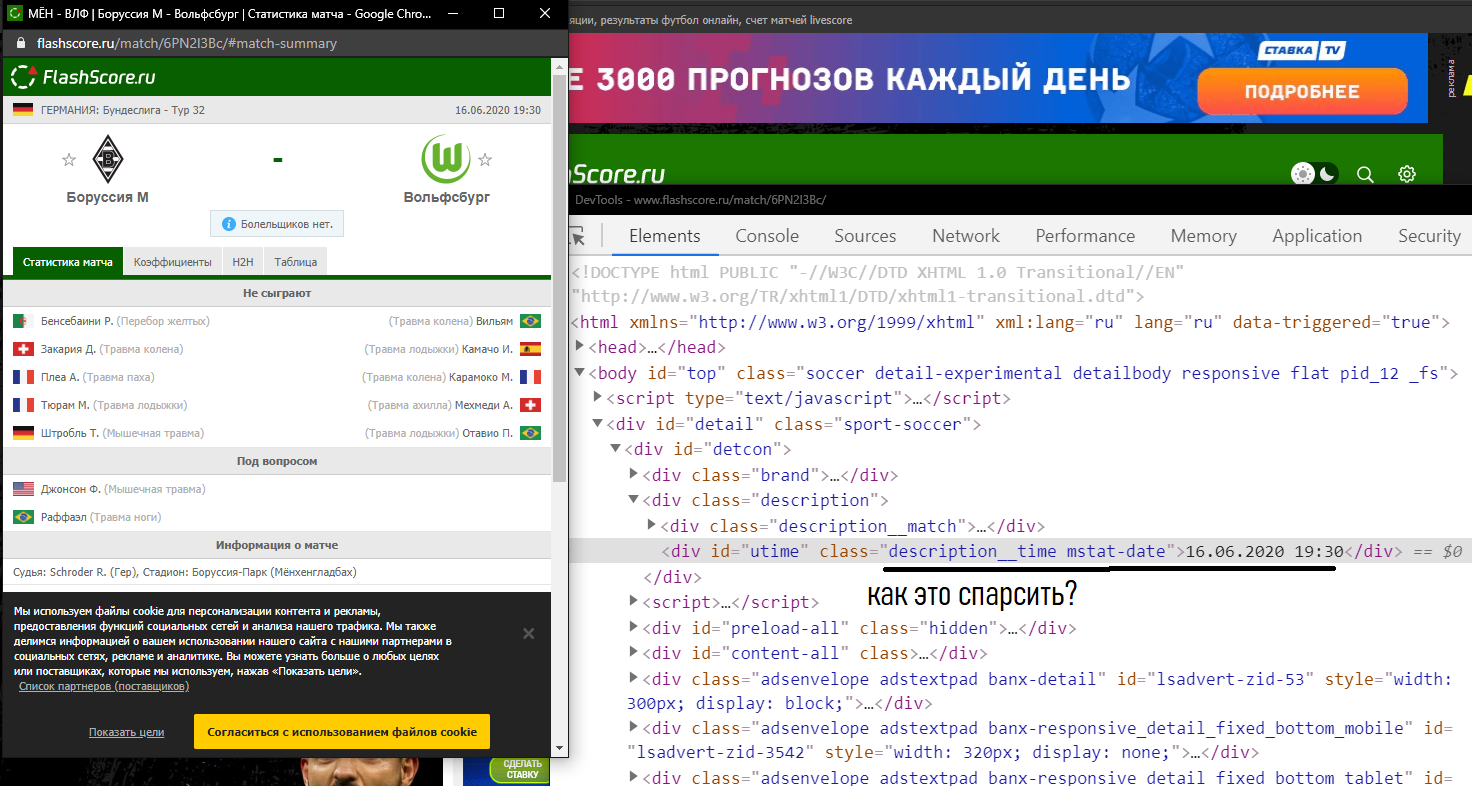
Answer the question
In order to leave comments, you need to log in
Because this data is not on the page. Crtl+U press and try to find them.
How to parse? - See what request the data comes from and repeat it. Either selenium
Hmm, my first reply got deleted... ok, good memory.
Why is this beautiful soup here? Selenium alone is enough, and if you decide to parse the page this way, then get it without Selenium, because this is a library for tests.
I would do this:
In general, I ask you, on behalf of the community, to google more, yandexit, binjit, and, at worst, dakdakgoshit before asking such a simple question.
PS Why are you working with this site?
timeStr = driver.find_element_by_id('utime').text
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question