Answer the question
In order to leave comments, you need to log in
Why is iowait growing?
There is a server on digitalocean on which there is an application under the docker. Nginx, postgres, php
Every day at exactly 5 am, severe problems with iowait begin, lasting about 30 minutes. It reaches 40% because of which the whole application lags.
I have already checked the entire application several times, there are no tasks at this time, and I did not find any assumptions about who can strain the disk at this time.
Moreover, the same problem exists on the 2nd server at exactly the same time and the same duration, but there iowait grows to 20%, everything is fine on the other servers.
It seems to load like a database, but there are no heaps of requests at this time and no commands are executed.
Before lags:
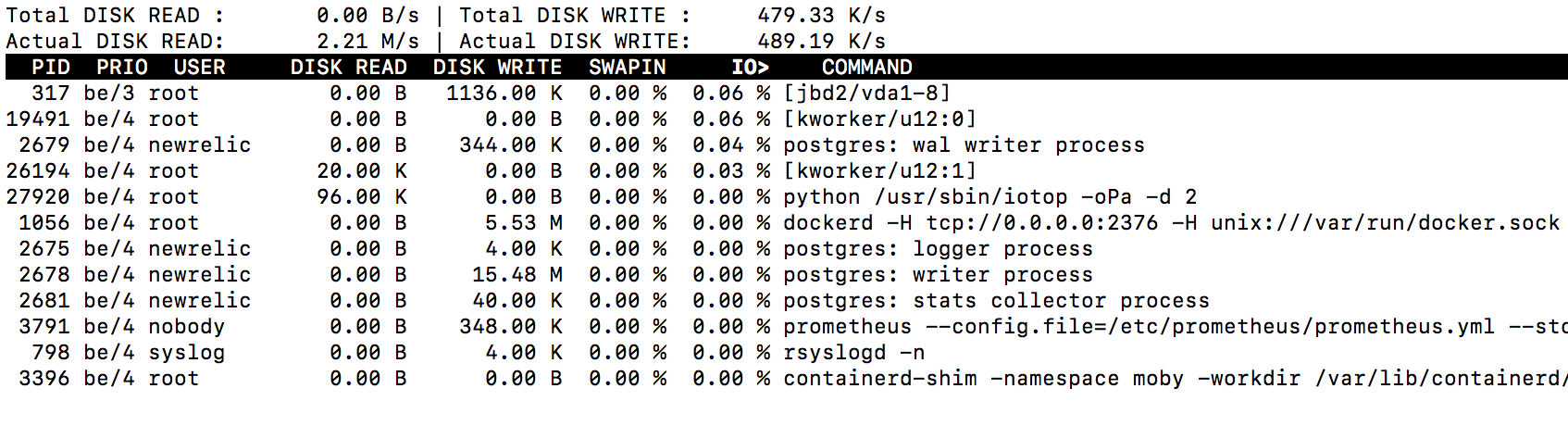
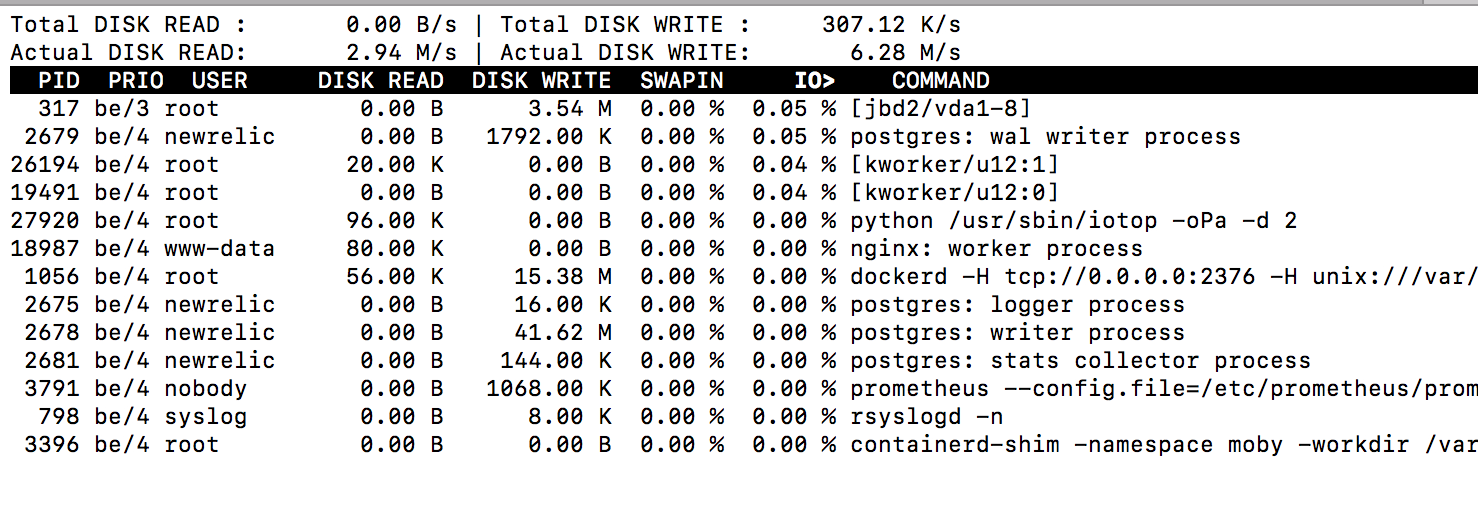
During:
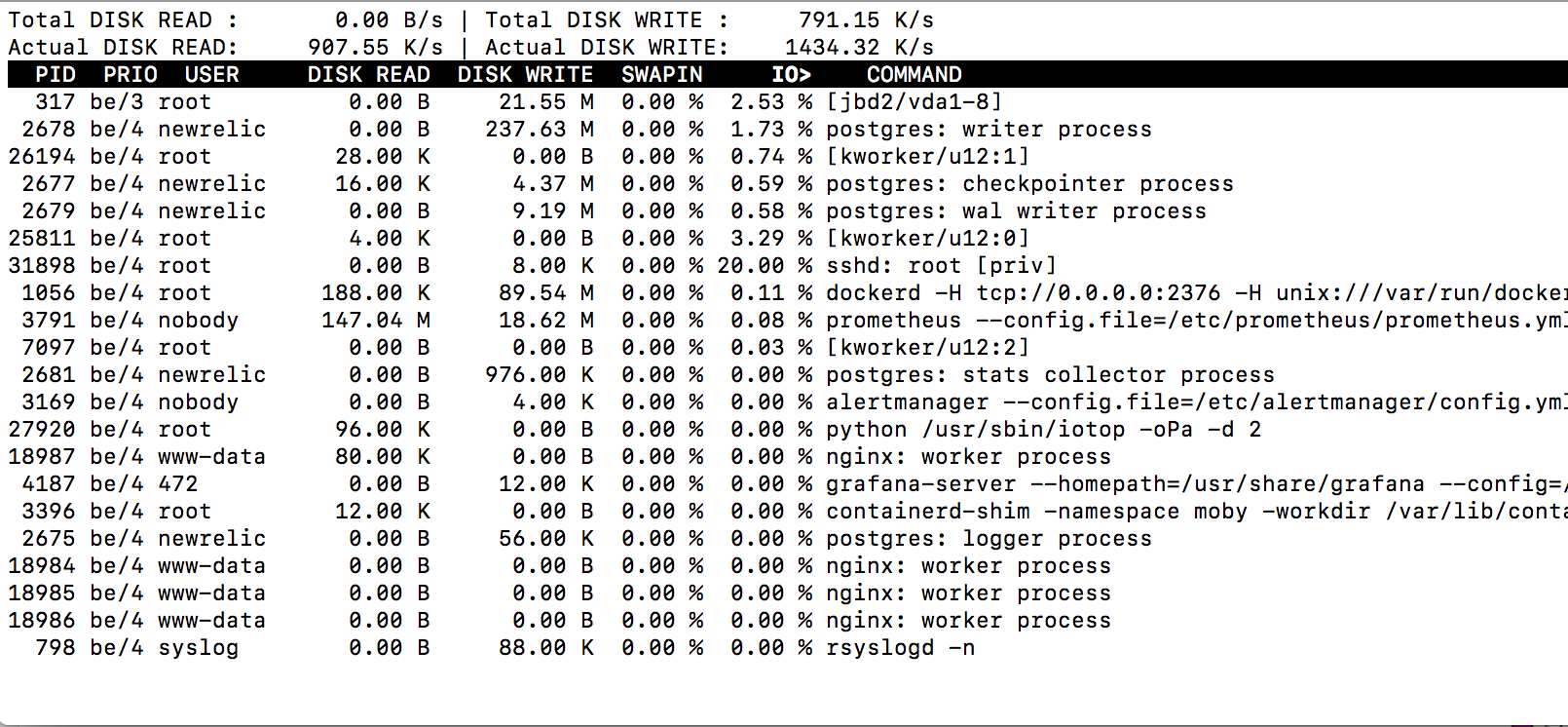
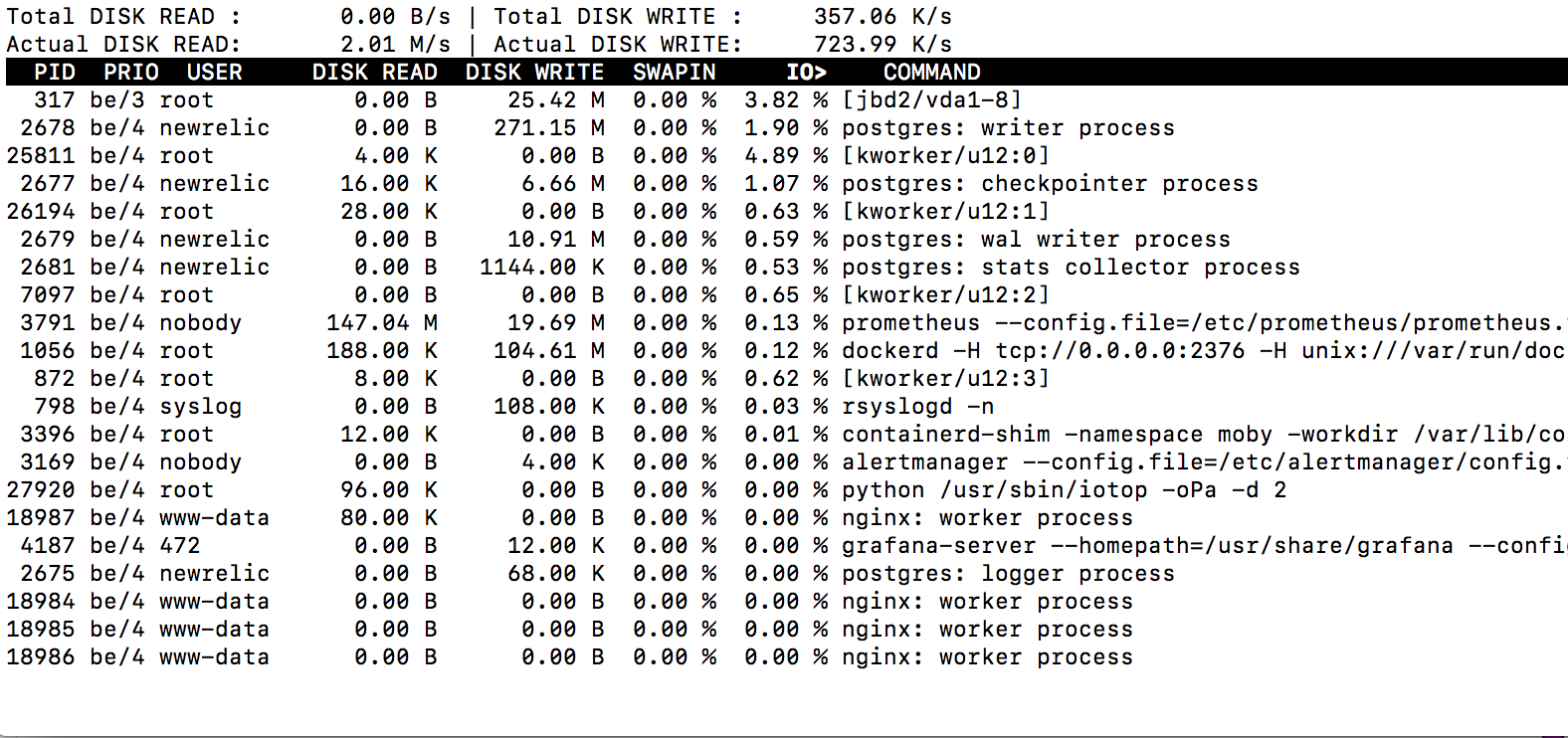
Answer the question
In order to leave comments, you need to log in
Problems with iowait are related to the busyness of the disk subsystem. Most likely at 5 am, tasks for data backup are launched
Here's what I googled about
postgres: writer process
The writer aka background writer process
Note that we assume that the high level concept of “checkpoints” together with the checkpointer process and its parameters are already familiar to you (as it's way more impactful compared to the writers). When not, I'd recommend digging into Postgres documentation here .
So to the writer. Introductory sentence in the documentation tells us:
There is a separate server process called the background writer, whose function is to issue writes of “dirty” (new or modified) shared buffers. It writes shared buffers so server processes handling user queries seldom or never need to wait for a write to occur. However, the background writer does cause a net overall increase in I/O load, because while a repeatedly-dirtied page might otherwise be written only once per checkpoint interval, the background writer might write it several times as it is dirtied in the same interval . …
In short – the writer moves some of the changed data (dirty buffers) already to the disk in the background, so that checkpoint process, happening at regular intervals, would have less work to do. All of this with the point that in the end user/application queries wouldn't need to suffer too much when checkpointer kicks in with its heavy IO requirements, when there are lots of buffers to be processed or checkpoint_completion_target is set too small. All this is relevant of course only when we're running a relatively busy database – for idling databases it wouldn't be a problem at all.
- look at the logs: /var/log or wherever you have them
- are the servers physically located in the same DC? maybe there is some kind of maintenance, although it is unlikely
- write to support
You have something like locate, slocate, mlocate. If there is, then they index it.
View iotop at this moment to understand exactly what is loading
. If there are no queries in the database, believe the vacuum, most likely it
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question