Answer the question
In order to leave comments, you need to log in
What is the error when requesting data using importxml in Google Docs?
Due to work needs, it is often necessary to refer to credit ratings, which is very tedious and time consuming due to a weak Internet connection and a low-powered computer. In this regard, I decided to compile a table in Google Docs along with the necessary data, always available for use.
I need to extract the following rating from the Fitch Ratings website:
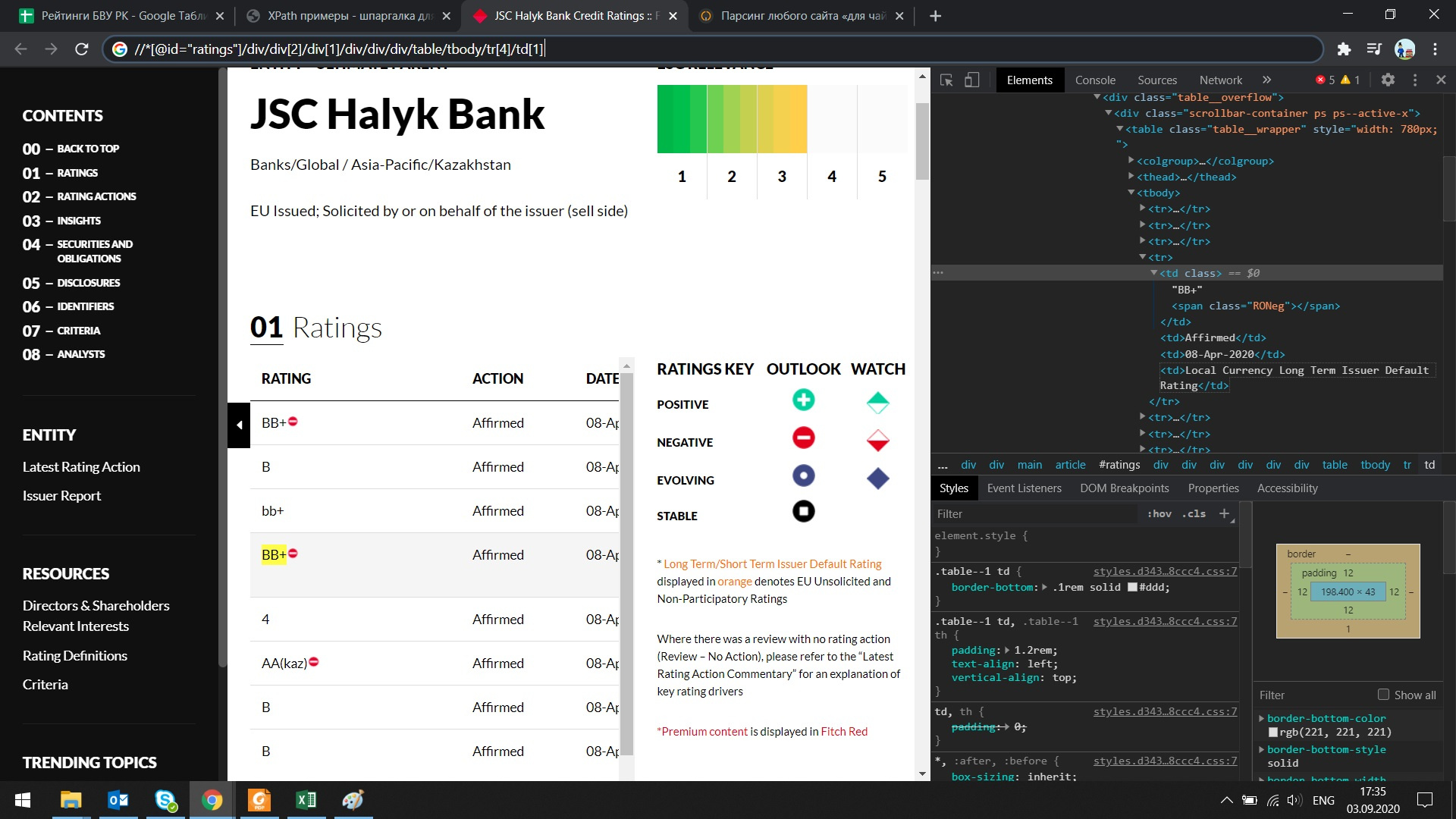
Link to the page:
Fitch Ratings
Using the Google Docs assistant, the desired result was not achieved:
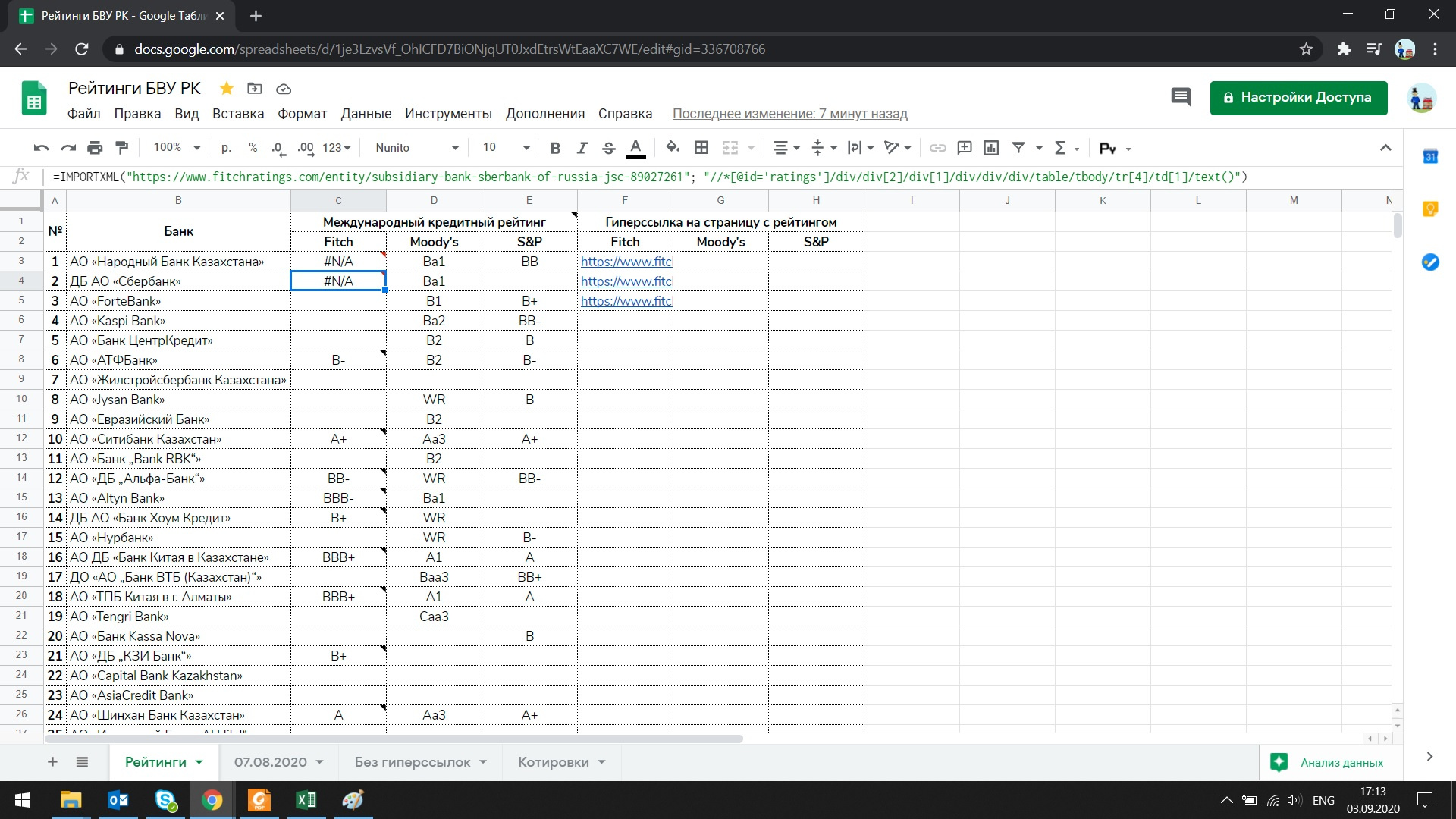
I also tried to use Full XPath in the query, nothing worked:
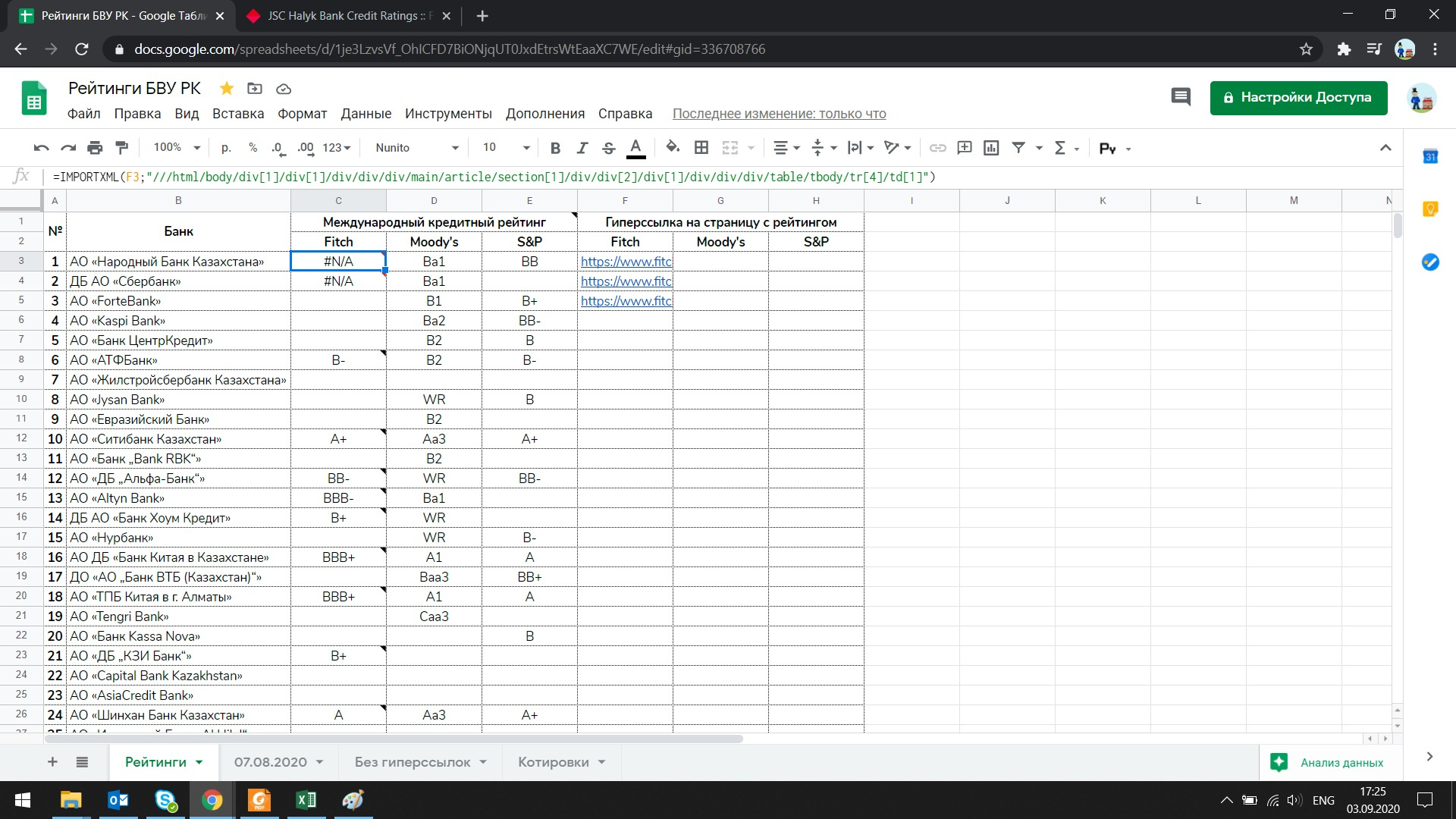
I tried otherwise, after reading materials on the network, it also did not work:
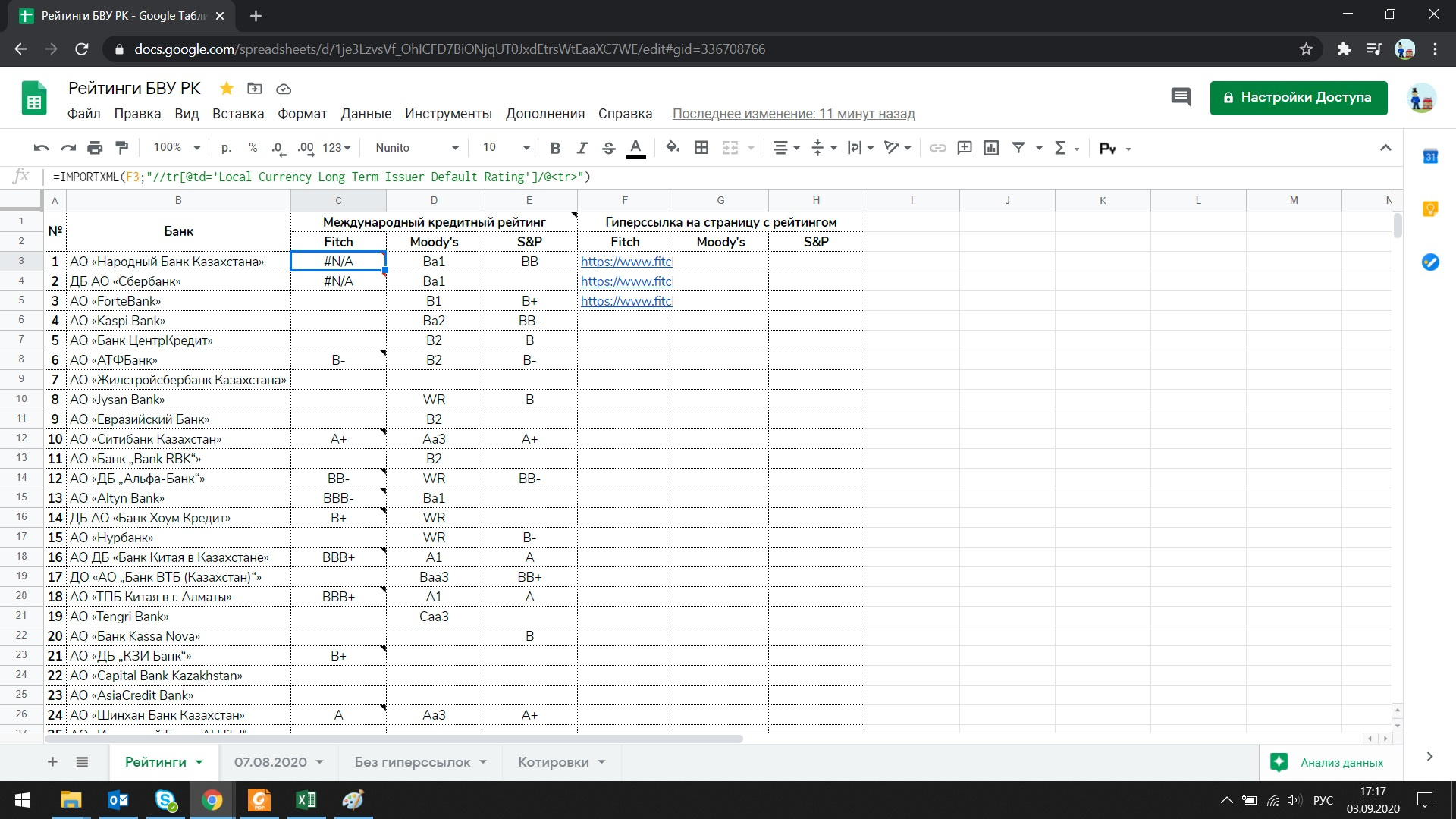
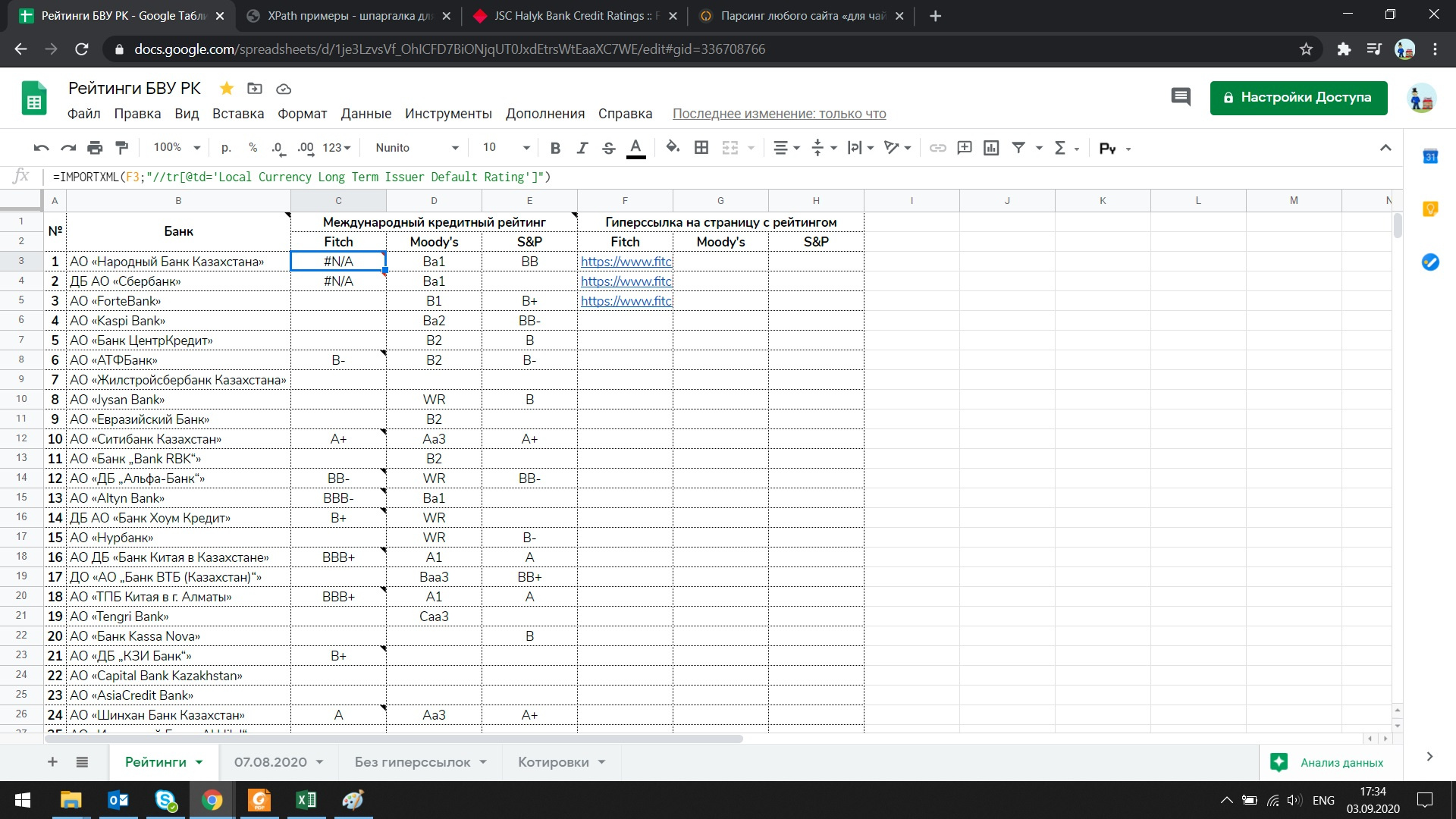
Tell me, please, where exactly and in what I made a mistake when compiling the request?
PS Also, if it's not difficult, can you tell me if it is possible to extract rating data from sites where authorization is required to access data (websites of S&P and Moody's Investors Service rating agencies)?
Thank you for your attention!
Answer the question
In order to leave comments, you need to log in
In this case, the problem is that IMPORTXML works with the source code for this page. which does not contain this information. They are loaded later from the API backing api.fitchratings.com and there is already a simple JSON.
PS If the site requires authorization for access and there are no authorization details and there is no hole on the site, then it will not work to pull out the data.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question