Answer the question
In order to leave comments, you need to log in
What is the correct way to use the parallel_for_each loop in the new C11 standard?
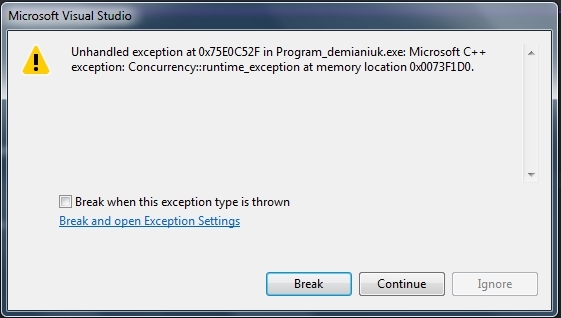
Good afternoon, in my program I wanted to use the new C11 standard to calculate pi, but I can’t cope with the parallel_for_each loop, because an error appears when using it.
Program code:
#include <amp.h>
#include <iostream>
#include "amp_tinymt_rng.h"
#include "amp_math.h"
#include <sstream>
#include <ctime>
#include <fstream>
#include <string>
#include <iomanip>
using namespace concurrency;
#define licznik1_PFEO 2 //(200/(2*2*2*2*2*2))
#define licznik2_GPU (5000000/(2*2*2*2*2*2*2*2*2))
#define n 2*2*2*2*2*2*2*2*2*2*2*2*2*2*2*2
// n CUDA Cores - Shader Processing Units
////////////////////////////////////////////////////////////////////
int main()
{
//////-accelerator-//////
accelerator default_device;
std::wcout << L"Using device : " << default_device.get_description() << std::endl;
if (default_device == accelerator(accelerator::direct3d_ref))
std::cout << "WARNING!! Running on very slow emulator! Only use this accelerator for debugging." << std::endl;
//////-FILE-//////
accelerator_view view = default_device.create_view(queuing_mode::queuing_mode_automatic);
FILE *ofile = NULL;
fopen_s(&ofile, "PiMonteCarlo.txt", "wt");
//////-Pi-//////
int seed = 5489;
double PI25DT = 3.141592653589793238462643;
double piMC;
double t1, t2; // time’s momemts
int k;
int licznik1;
double trafenie_sum, N;
N = n*licznik1_PFEO*licznik2_GPU;
trafenie_sum = 0;
extent<1> e_trafenie_idx_sum_h(n);
array<double, 1> trafenie_idx_sum_d(e_trafenie_idx_sum_h);
std::vector<double> trafenie_idx_sum_h(e_trafenie_idx_sum_h.size());
t1 = clock();
for (licznik1 = 1; licznik1 <= licznik1_PFEO; licznik1++)
{
tinymt_collection<1> myrand(e_trafenie_idx_sum_h, seed + licznik1);
//////////////////////////parallel_for_each////////////////////////////
parallel_for_each(e_trafenie_idx_sum_h, [=, &trafenie_idx_sum_d](index<1> idx) restrict(amp)
{
auto t = myrand[idx];
float x, y;
int licznik2;
int trafenie_idx = 0;
for (licznik2 = 0; licznik2 < licznik2_GPU; licznik2++)
{
x = t.next_single();
y = t.next_single();
if (x*x + y*y <= 1) trafenie_idx++;
} //end for licznik2
trafenie_idx_sum_d[idx] = trafenie_idx;
});
//////////////////////////parallel_for_each////////////////////////////
copy(trafenie_idx_sum_d, trafenie_idx_sum_h.begin());
for (k = 0; k < n; k++) trafenie_sum = trafenie_sum + trafenie_idx_sum_h[k];
} // end for licznik1
piMC = (4 * trafenie_sum) / N;
t2 = clock();
fprintf_s(ofile, "%.0f wielkosc_statystiki; czas %.5lf [sec];\n", N, ((t2 - t1) / CLOCKS_PER_SEC));
fprintf_s(ofile, "seed=%.d generator licb losowych 'TinyMT', a variant of Mersenne twister;\n", seed);
fprintf_s(ofile, "pi=%.10f; Epi=%.10f; \n", piMC, ((100 * (PI25DT - piMC)) / PI25DT));
fprintf_s(ofile, "liczba_serii * liczba_cores * liczba_losowan_w_serii = wielkosc_statystiki \n");
fprintf_s(ofile, "%d * %d * %d = %.0f; \n", licznik1_PFEO, n, licznik2_GPU, N);
fclose(ofile);
return 0;
}
Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question