Answer the question
In order to leave comments, you need to log in
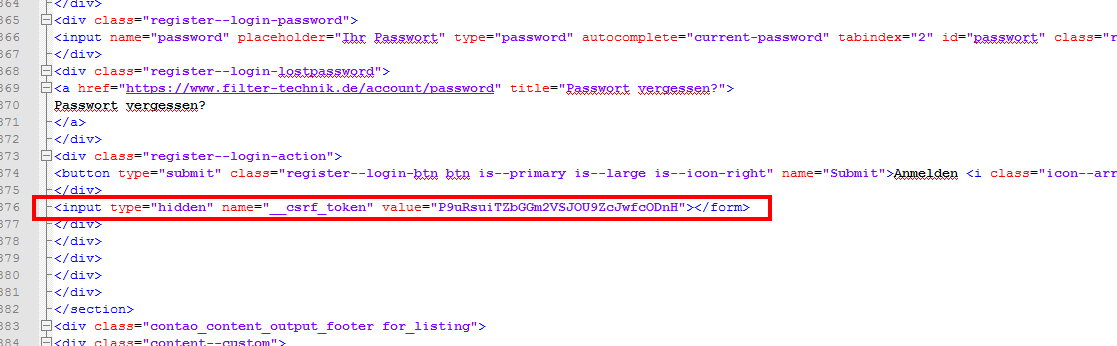
What is the correct way to read the file along with hidden __csrf_token?
–ø—ã—Ç–∞—é—Å—å –Ω–∞–ø–∏—Å–∞—Ç—å –∞–≤—Ç–æ–º–∞—Ç–∏—á–µ—Å–∫–∏–π –≤—Ö–æ–¥ –Ω–∞ —Å–∞–π—Ç —Å –¥–∞–ª—å–Ω–µ–π—à–∏–º –ø–∞—Ä—Å–∏–Ω–≥–æ–º —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤.
–ê–≤—Ç–æ—Ä–∏–∑–∞—Ü–∏–æ–Ω–Ω–∞—è —Ñ–æ—Ä–º–∞ –∫—Ä–æ–º–µ –ª–æ–≥–∏–Ω–∞ –∏ –ø–∞—Ä–æ–ª—è –ø–µ—Ä–µ—Å—ã–ª–∞–µ—Ç hidden __csrf_token.
–í–æ–ø—Ä–æ—Å 1
–ü—Ä–∞–≤–∏–ª—å–Ω–æ –ª–∏ —á—Ç–æ —Å–Ω–∞—á–∞–ª–∞ –Ω—É–∂–Ω–æ —ç—Ç–æ—Ç –≤–µ–±—Å–∞–π—Ç —Å—á–∏—Ç–∞—Ç—å GET –∑–∞–ø—Ä–æ—Å–æ–º, –ø–æ—Ç–æ–º –≤—ã—Ç–∞—â–∏—Ç—å –∏–∑ HTML —Ç–µ–∫—Å—Ç–∞ __csrf_token –∏ –µ–≥–æ –≤–º–µ—Å—Ç–µ —Å –ª–æ–≥–∏–Ω–æ–º –∏ –ø–∞—Ä–æ–ª–µ–º –æ—Ç–ø—Ä–∞–≤–∏—Ç—å —Å–ª–µ–¥—É—é—â–∏–º –∑–∞–ø—Ä–æ—Å–æ–º –¥–ª—è –≤—Ö–æ–¥–∞ –Ω–∞ —Å–∞–π—Ç?
–µ—Å–ª–∏ –Ω–µ–ø—Ä–∞–≤–∏–ª—å–Ω–æ, —Ç–æ –∫–∞–∫ —Å–¥–µ–ª–∞—Ç—å?
–í–æ–ø—Ä–æ—Å 2
–ü—Ä–µ–¥–ø–æ–ª–∞–≥–∞—è, —á—Ç–æ –º–æ—è –ª–æ–≥–∏–∫–∞ –≤ –í–æ–ø—Ä–æ—Å–µ 1 –ø—Ä–∞–≤–∏–ª—å–Ω–∞—è, –ø—ã—Ç–∞—é—Å—å –Ω–∏–∂–µ—É–∫–∞–∑–∞–Ω–Ω—ã–º –∫–æ–¥–æ–º —Å—á–∏—Ç–∞—Ç—å —Å–∞–π—Ç.
import requests
from bs4 import BeautifulSoup
s = requests.Session()
_url_00 = "https://www.filter-technik.de/account"
x_00 = s.get(_url_00)
with open("_ELSAESSER_000.html", "w", encoding='utf-8') as f:
f.write(x_00.text)
soup_00 = BeautifulSoup(x_00.text, "html.parser")
_match = soup_00.find("__csrf_token")
print(_match)
input()
Answer the question
In order to leave comments, you need to log in
–°–æ–±—Å—Ç–≤–µ–Ω–Ω–æ –ø–æ—Å–ª–µ –º–∏–Ω—É—Ç—ã –≤ –∏–Ω—Å–ø–µ–∫—Ç–æ—Ä–µ –æ–∫–∞–∑–∞–ª–æ—Å—å, —á—Ç–æ —Ç–æ–∫–µ–Ω –æ—Ç–¥–∞—ë—Ç—Å—è –≤ –∑–∞–≥–æ–ª–æ–≤–∫–µ –æ—Ç–≤–µ—Ç–∞.
r = requests.get('https://www.filter-technik.de/csrftoken')
token = r.headers['X-Csrf-Token']AWEme AWEme
–ë–ª–∞–≥–æ–¥–∞—Ä—é –≤–∞—Å. –î–ª—è –í–∞—Å —ç—Ç–æ –æ–¥–Ω–∞ –º–∏–Ω—É—Ç–∞, –¥–ª—è –º–µ–Ω—è-—á–∞–π–Ω–∏–∫–∞ –Ω–µ—Å–∫–æ–ª—å–∫–æ –¥–Ω–µ–π.
–í—Å—ë —Ä–∞—Å–Ω–æ –Ω–µ —Å–æ–≤—Å–µ–º –ø–æ–Ω—è–ª –∫–∞–∫ –≤—ã –ø—Ä–∏—à–ª–∏ –∫ —ç—Ç–∏–º –¥–≤—É–º —Å—Ç—Ä–æ–∫–∞–º
–∏
–ï—Å–ª–∏ –Ω–∞–π–¥–µ—Ç–µ –µ—â–µ –º–∏–Ω—É—Ç—É, –ø–æ—è—Å–Ω–∏—Ç–µ –ø–æ–∂-—Å—Ç–∞ –≤–∫—Ä–∞—Ç—Ü–µ.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question