Answer the question
In order to leave comments, you need to log in
Parsing html with Selenium+Python, incorrect return?
Hello! Difficulty encountered when trying to get references from hrefelement attributes a.
Link to the page in the repository on the git. (Pre-moderation swears, apparently because of the resource domain)
<selenium.webdriver.remote.webelement.WebElement (session="45a0063f8da9f78a78c38b201240c24a", element="6b43db73-2b1a-4886-9237-f493f7693539")>hrefI can not get from it. Tell me, what could be wrong? Perhaps there is some other way to get links from elements? Answer the question
In order to leave comments, you need to log in
Accordingly, I can’t get href from it
<div>with class testCard. It divdoes not and never has the attribute href. 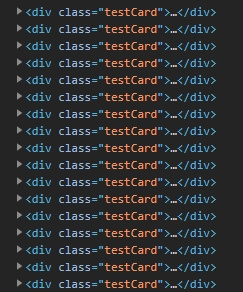
class. hreffrom a nested divelement а, 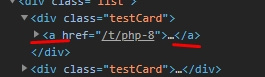
divelement a, then take them from them href.for el in slide_elems:
# Находим вложенный тег <a>
tag_a = el.find_element_by_tag_name('a')
print(tag_a.get_attribute('href'))The href attribute is only on the anchor, which is under testCard.
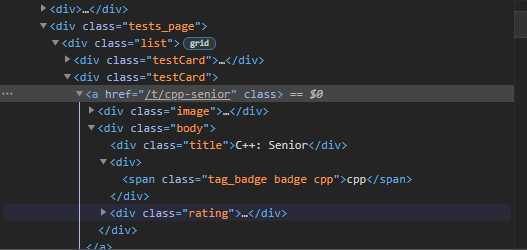
XPath for it:
//*[@class='testCard']/a
Here you write a string representation of a list with WebElement elements to a file. And you need to write the 'href' attribute.
def parse(self):
self.go_to_questsions_page()
slide_elems = self.driver.find_elements_by_class_name("testCard")
f = open("text.txt", "w")
f.write(str(slide_elems))
for el in slide_elems:
print(el.get_attribute('href'))Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question