Answer the question
In order to leave comments, you need to log in
How to understand what parameters to change in order to achieve network convergence?
Here I am doing the example from these 2 articles: https://habr.com/ru/post/312450/ https://habr.com/ru/post/313216/
Briefly context:
Well, ok, I'll try:
there is a neuron 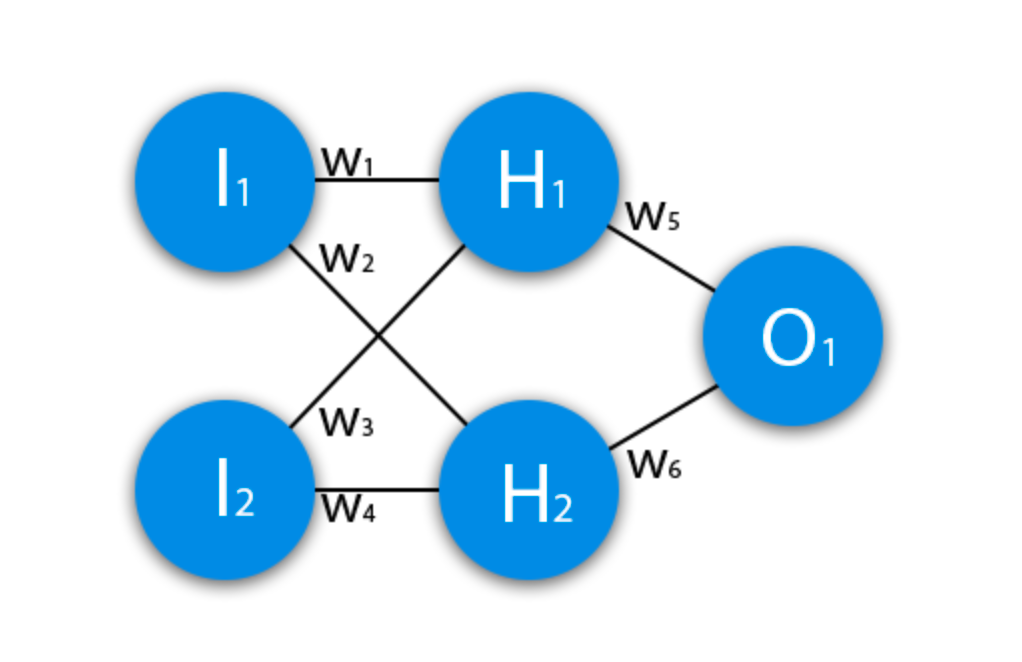
trying it teach XOR operations.
To train it, I use the inverse distribution method.
If you apply the same combination (01) to the input, then there is convergence (ie, the error decreases as it should be).
But if you start serving with sets 01, 00, 10, 11, then the convergence immediately disappears.
What I tried: played with the number of iterations, changed the learning rate, changed the moment, added bias neurons.
So far, none of this has helped, so I decided to post a question here.
I do not understand how to achieve convergence. Neurons are all exactly as in the articles. Probyval to change the learning rate, the moment. Does not help. https://habr.com/ru/post/313216/#comment_20654001 here I asked the author a question, but I'm not sure that I will get an answer from him, so I duplicate it here. Thanks in advance for your reply.
Answer the question
In order to leave comments, you need to log in
Maybe the error is still somewhere in the code?
The fact that the model converges on the same example does not mean anything - it simply adjusts the bias on the output neuron. The input data is not needed if the output is always the same.
Try to initialize the weights with some known values, calculate the output/gradients analytically yourself and compare with what happens in the simulation.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question