Answer the question
In order to leave comments, you need to log in
How to train tesseract for your font?
Good afternoon. I'm trying to train tesseract v5 for my font, because standard even after image processing show an incorrect result. Can someone tell me how it's done or throw a manual, for several days I've been looking everywhere to no avail.
Answer the question
In order to leave comments, you need to log in
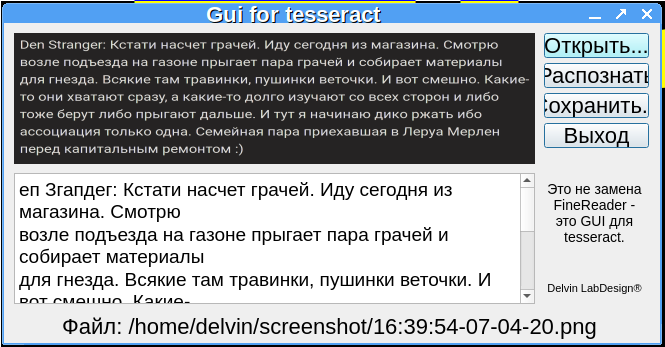
tesseract 4.1.1, pytesseract 0.3.0 eats everything (well, almost)
Code:
def ocr(self):
global dtout
pytesseract.pytesseract.tesseract_cmd = '/usr/bin/tesseract'
dtout = pytesseract.image_to_string(Image.open(fname), 'rus+eng+chi_tra+jpn')
self.ui.textOut.setText(dtout)
For special tasks, the Gamera framework may be suitable . You can even recognize hieroglyph scripts and various historical inscriptions. But this is more for researchers.
Learning takes place interactively.
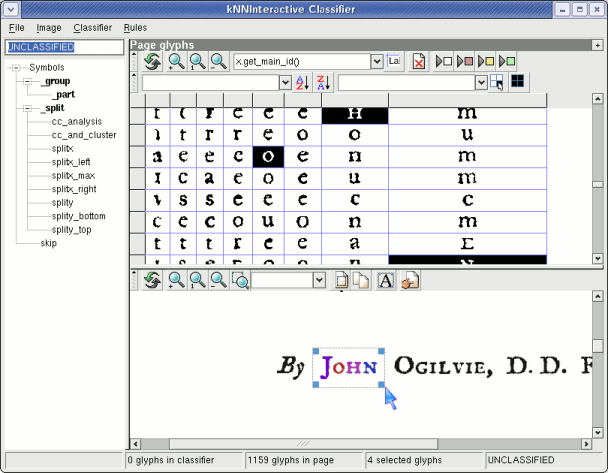
https://gamera.informatik.hsnr.de/docs/gamera-docs...
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question