Answer the question
In order to leave comments, you need to log in
How to split an Excel cell using Pandas?
Good time stock. Please tell me how to take some columns from Excel using Python and the Pandas library, break them into the Last Name, the first letter of the first name and patronymic. So that they were each in their own line.
In general, I need to compare two files, and for this it is necessary, as I think, to bring them to a common template. Maybe I'm wrong, but this method works in Excel. Yes, and everything would be fine, but you have to do this action 10-15 times.
At this stage I'm trying to convert one file, it should ideally turn out like 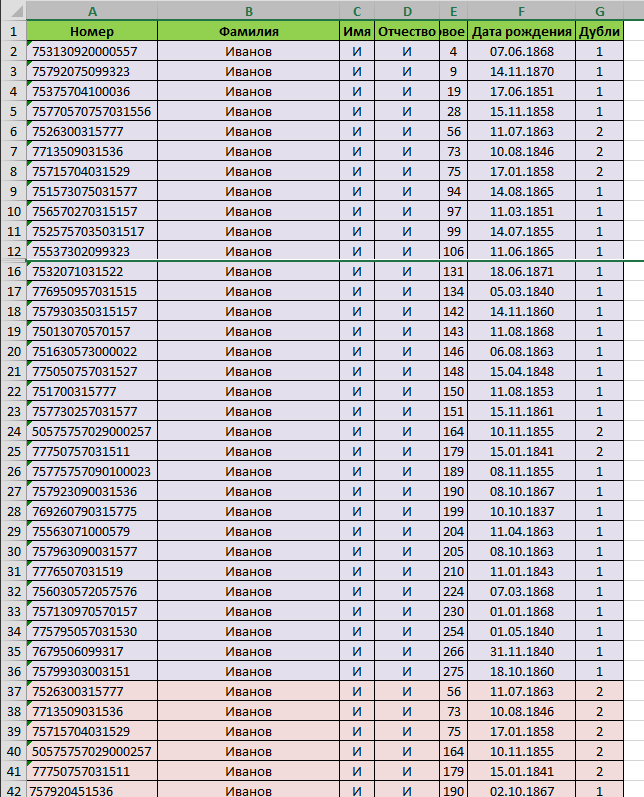
this. At the moment, all I have is the 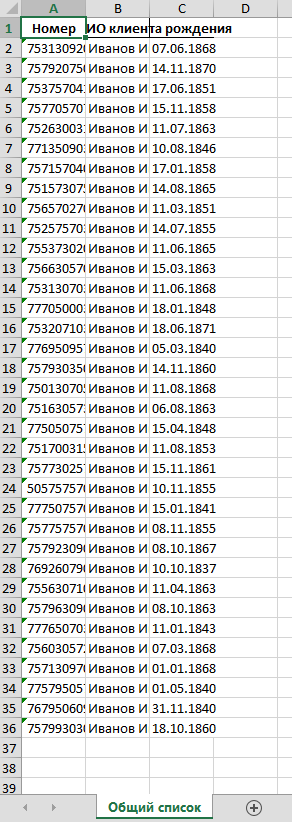
source file looks like this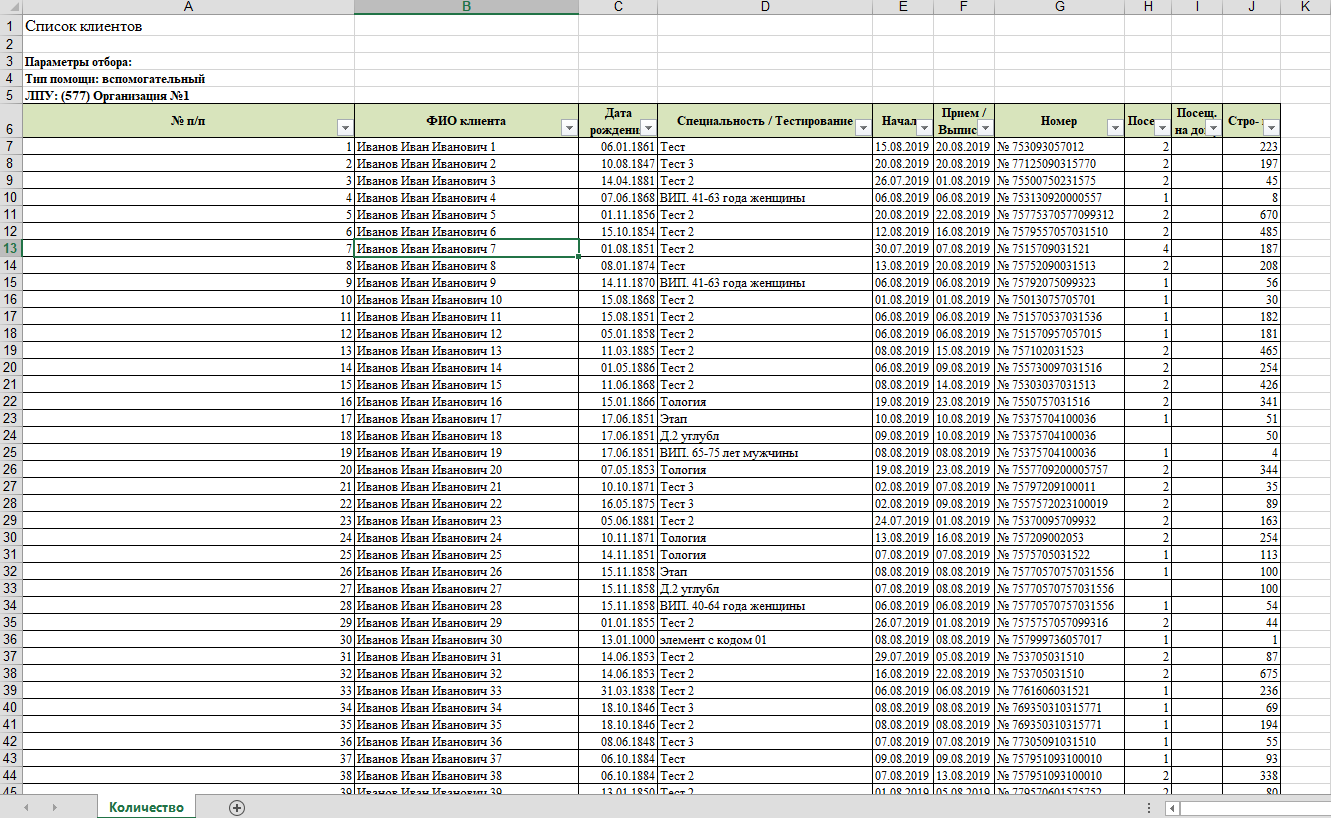
Yes, there are some questions about the code itself. I do not understand line 14 at all, namely why after .str when I put . replace is not highlighted in tooltips when pressing ctrl+space. It looks like it doesn't exist, but it works.
import pandas as pd
# Опция отвечающая за вывод всех колонок в консоли
pd.set_option('display.expand_frame_repr', False)
# Указываем место расположения файла
pathFileOpen = r"E:\Learn_Python\tmp\Cписок август.xlsx"
pathFileSave = r"E:\Learn_Python\tmp\Список август (автоматический вариант).xlsx"
# Читаем данные из файлов с помощью панды
wb = pd.read_excel(pathFileOpen, sheet_name='Количество', header=5, usecols="A:D, G, H")
# Разбиваем на отдельные колонки ФИО
new_concatFrame = wb['ФИО клиента'].str.split(' ', expand=True)
# Называем вновь созданные колонки
new_concatFrame.columns = ['Фамилия', 'Имя', 'Отчество', 'Удалить']
# Присваиваем переменной DataFrame переменные wb и new_concatFrame для последующей склейки
DataFrame = [wb, new_concatFrame]
# Склеиваем двае переменные методом concat. Параметр axis=1 говорит о том что необходимо добавить столбцы с созданными именами
concatFrame = pd.concat(DataFrame, axis=1)
keysFilter = ['ВИП. 18-39 лет женщины',
'ВИП. 18-39 лет мужчины',
'ВИП. 40-62 года мужчины',
'ВИП. 40-64 года женщины',
'ВИП. 41-63 года женщины',
'ВИП. 41-63 года мужчины',
'ВИП. 45,55 лет мужчины',
'ВИП. 50,60,64 года мужчины',
'ВИП. 65-75 лет женщины',
'ВИП. 65-75 лет мужчины',
'ВИП. 66-74 лет женщины',
'ВИП. 76 лет и > женщины',
'ВИП. 76 лет и > мужчины']
# Фильтруем строки по заданным ключам
concatFrame = concatFrame.loc[concatFrame['Специальность / Тестирование'].isin(keysFilter)]
# Выбираем необходимые колонки для копирования
concatFrame = concatFrame
# for i in concatFrame:
# print(concatFrame[i][:1])
# Уюираем значок № из файла
for column in concatFrame.columns:
concatFrame[column] = concatFrame[column].str.replace('№', '')
concatFrame.to_excel(pathFileSave, sheet_name='Общий список', index=False, )
print(concatFrame)
# не работает (((
# writer = pd.ExcelWriter(pathFileSave, engine='xlsxwriter')
# concatFrame.to_Excel(writer, sheet_name='Общий список')
# writer.save()
print(type(concatFrame))
print(isinstance(concatFrame, list))
# list1 = []
# for i in fioRedact['Фамилия']:
# for cell in i:
# list1.append(cell.value)
#
# # Сохраняем полученный файл
# finalDF.to_excel(pathFileSave, sheet_name='Общий список', index=False, columns=['Полис', 'Дата рождения', 'Фамилия', 'Имя', 'Отчество'])
# writer = pd.ExcelWriter(pathFileSave)
# finalDF.to_Excel(writer, sheet_name='Общий список')Answer the question
In order to leave comments, you need to log in
To be honest, I didn’t specifically try on your files (there is no possibility now), so I sketched in the console:
>>> import pandas
>>> df = [{'name': 'Ivanov I', 'age': '136', 'iq': 0}]
>>> df = pandas.DataFrame(df)
>>> df
name age iq
0 Ivanov I 136 0
>>> ndf = pandas.DataFrame(df.name.str.split().tolist(), columns=['p', 'n'])
>>> ndf
p n
0 Ivanov I
>>> ndf.p = ndf.p.str[0]
>>> ndf
p n
0 I I
1 A A
2 N N
>>> res = pandas.concat([df, ndf], sort=False, axis=1)
>>> res
name age iq p n
0 Ivanov I 136 0 I I
>>> res = res
>>> res
name p n age iq
0 Ivanov I I I 136 0Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question