Answer the question
In order to leave comments, you need to log in
How to scrape data from a website?
Data must be obtained from here smarthand.pro/ps/#Time2goo
import requests
from bs4 import BeautifulSoup
URL = 'https://smarthand.pro/ps/#Time2goo'
r = requests.get(URL)
soup =BeautifulSoup(r.text, 'html.parser')
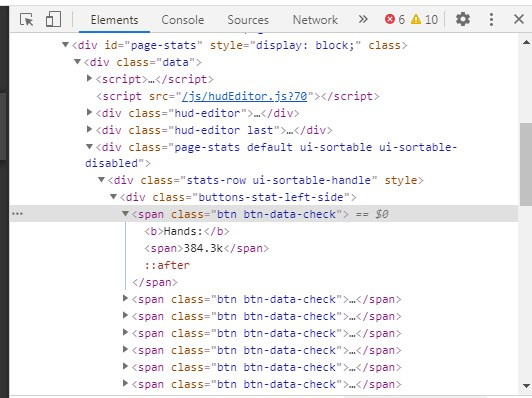
items = soup.find('div', class_='buttons-stat-left-side')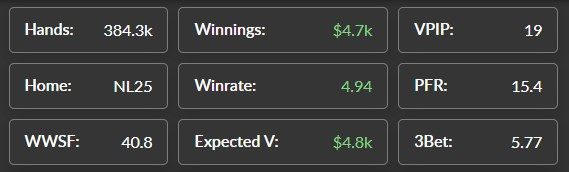
Answer the question
In order to leave comments, you need to log in
In the dev tools, the network tab and the xhr section
Refresh the page, see the necessary requests
Repeat them using requests.
I don't know how to get them from there. Searching for a div by a given class does nothing.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question