Answer the question
In order to leave comments, you need to log in
How to recognize text in PDF and export data to csv?
I categorically welcome, I ask you to direct me on the path, what tools and frameworks to use to optimize routine tasks, preferably using python at the amateur level or possibly other ready-made tools, where to read more.
Problem:
There are a huge number of digitized documents that need to be recognized (tried with TesseractOCR, unsuccessfully) automatically for certain fields and entered into the site-form without having access to the database.
Question:
I just ask you to acquaint with a similar experience how to recognize a document by tags, export it to from cvs / exel etc, and then to an html form.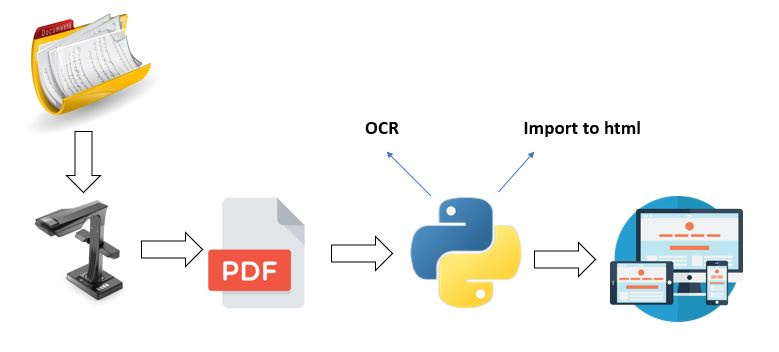
Answer the question
In order to leave comments, you need to log in
export to from cvs/exel etc, and then to html form.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question