Answer the question
In order to leave comments, you need to log in
How to put multiline text in one cell in CSV?
There is such a parser in Python:
with open(INPUT) as file:
lines = [line.strip() for line in file.readlines()]
data_dict = []
count = 0
with open(FILE, mode='w') as csv_file:
for line in lines:
q = requests.get(line)
result = q.content
soup = BeautifulSoup(result, 'lxml')
cross = soup.find_all('a', class_='***')
count += 1
print(f'#{count}: {line} is done!')
data_dict.append(cross)
writer = csv.writer(csv_file)
writer.writerow([cross])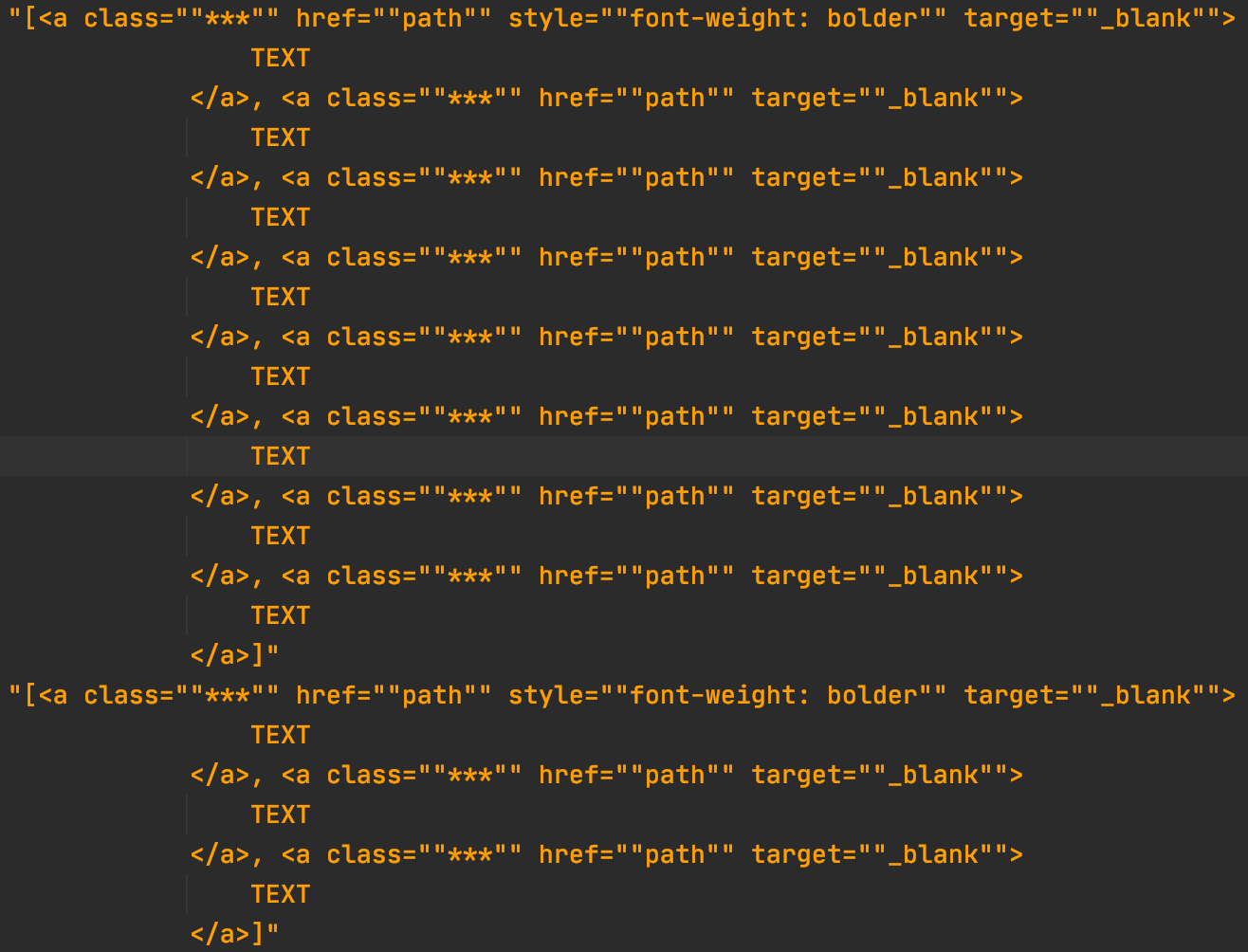

Answer the question
In order to leave comments, you need to log in
The CSV format is not very suitable for multi-line cells. I would say he does not support it. Write directly in Excel format https://xlsxwriter.readthedocs.io/index.html
Answering the question in the title:
Encode the text so that there are no invalid characters left in it, i.e. characters that are used in the storage format itself as control characters. You can use percent-encodig, you can use JSON, you can use base64. And it is probably better to immediately save the data to a database or an Excel spreadsheet.
But, if you need the text to remain as readable as possible (for example, so that it can be corrected manually in the editor), for example, for the csv format, which is often chosen for this reason, then you can use this trick:
s = "aaa\n\nbbb\tccc" # Строка с запрещёнными символами
rs = repr(s) # "Закодированная" строка: "'aaa\\n\\nbbb\\tccc'"
# Чтобы раскодировать:
import ast
decoded = ast.literal_eval(rs)
>> print(s)
aaa
bbb ccc
>> print(rs)
'aaa\n\nbbb\tccc'
>> print(decoded)
aaa
bbb cccDidn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question