Answer the question
In order to leave comments, you need to log in
How to properly build a Pipeline?
I have already faced the problem of creating a normal Pipeline in sklearn many times, and this time I decided to ask for advice here. How to make a complete Pipeline that receives raw data as input, fills in the gaps, divides the features into several columns (Categorical, real, etc.), then processes them separately and glues the data together so that it can be given to the model. I would like some links to projects where this is present.
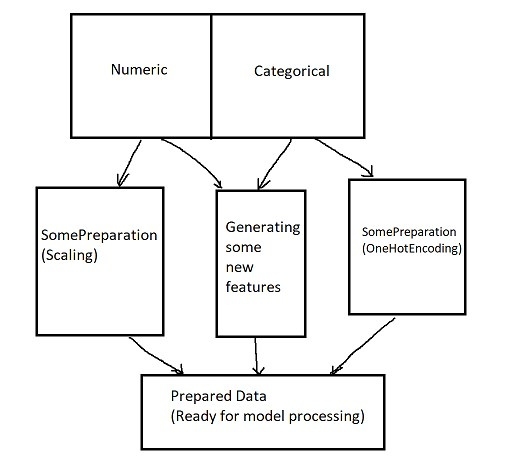
PS: Usually in all tutorials, the data is processed in pandas dataframe, and then it is fed into the model, but there are no normal pipelines, that's why I'm writing here :)
Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question