Answer the question
In order to leave comments, you need to log in
How to parse this image if it is not in the html file?
Here is the site: https://gdz-putina.net/5-klass-biologiya-pasechnik...
I wrote the code
def get_link(url):
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser').find('div', class_='task', id='task')
links = []
for i in soup.find_all('a', href=True):
a = i['href']
link = url + a
links.append(link)
return links<div id='media-6' class='media media-6 media-center'></div>
<div class="task"
id="task"
data-host="//gdz-putina.net"
></div>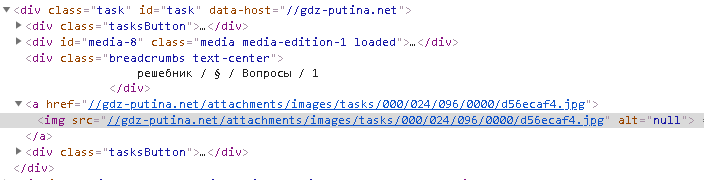 How do I parse a link to an image?
How do I parse a link to an image?
Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question