Answer the question
In order to leave comments, you need to log in
How to parse text from link image?
I can’t pull out the title, link, numbers, or an empty list, or something left, or the get_text () attribute of the error, I can’t figure out how to do it.
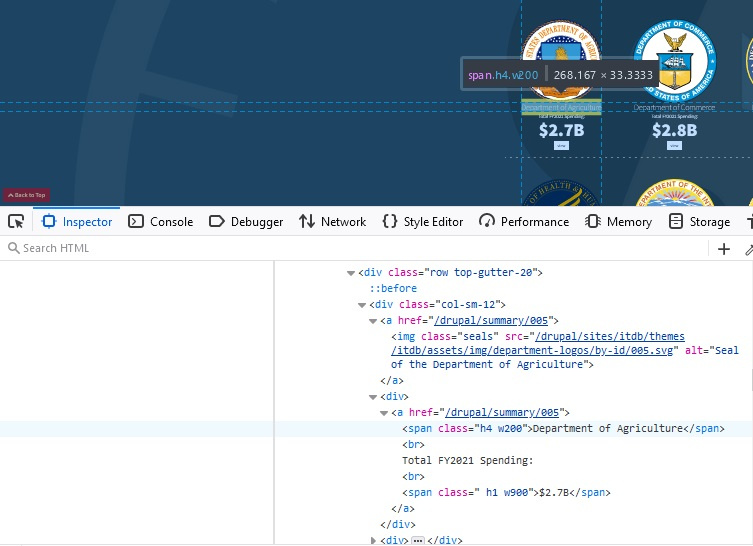
import requests
from bs4 import BeautifulSoup
import csv
HOST = 'https://itdashboard.gov/'
URL = 'https://itdashboard.gov/#home-dive-in'
HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0'
}
def get_html(url, params=''):
r = requests.get(url, headers=HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='tuck-5')
cards = []
print(items)
html = get_html(URL)
print(get_content(html.text))Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question