Answer the question
In order to leave comments, you need to log in
How to parse multiple links on the same site?
Hello.
There is the following task (I practice): to parse the name of the vacancy and its link from the site.
The initial link to the site shows vacancies in one city. After successfully parsing vacancies from this city, I press the button of another city to parse the next portion of vacancies. And nothing happens at this stage - an error appears:
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
Logically, I wanted to move from one city to another and parse vacancies. Next, I will add everything to the list and load it into the database.
The second problem:
When parsing a vacancy, the title drags the texts of child elements with it. How can this be banned?
Result now:
'title': 'Director, Reward & People OperationsLocationBerlin, Vienna, BarcelonaTime TypeFull time'
Desired result:
'title': 'Director, Reward & People Operations'
Problem 3:
Using absolute path in xpath. Until I touch it, I'll fix it later.
It is clear that the code can be made much more efficient, but I do not have such a task now. I would like to get a working script first. But I will be grateful for useful tips on organizing this code.
Thank you.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from datetime import date
import sqlite3
chromedriver = 'C:\\chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get('https://n26.com/en/careers/locations/57663')
while True:
try:
WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div/div[2]/div/div[3]/button[1]'))).click()
except TimeoutException:
break
jobs = []
section = driver.find_elements_by_xpath("//ul[@class='ah aj al an ap aq jp kd ke kf kg']//li")
for i in section:
a = i.find_element_by_css_selector("a")
job = {
'title': a.get_property('text'),
'href': a.get_attribute("href")
}
print(job)
jobs.append(job)
driver.execute_script("window.scrollTo(0, 300)")
driver.find_element_by_xpath("//a[@href='/en/careers/locations/49747']").click()
section2 = driver.find_elements_by_xpath("//ul[@class='ah aj al an ap aq jp kd ke kf kg']//li")
for i in section:
b = i.find_element_by_css_selector("a")
job2 = {
'title': b.get_property('text'),
'href': b.get_attribute("href")
}
print(job2)
jobs.append(job2)
# print(jobs)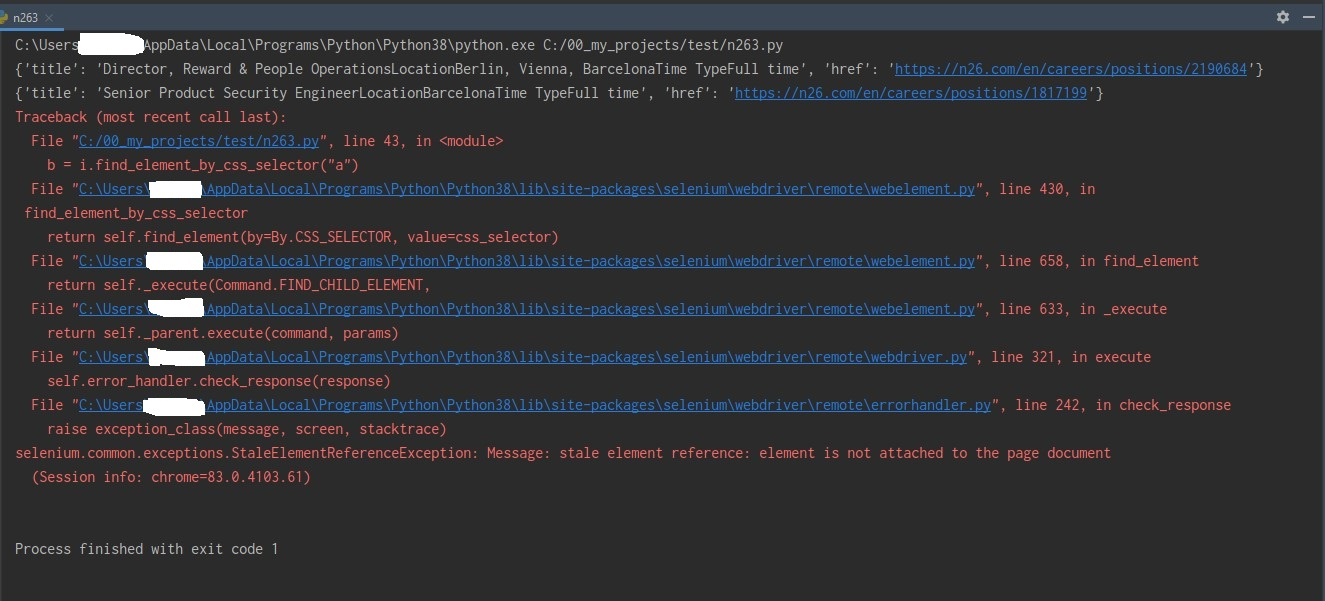
Answer the question
In order to leave comments, you need to log in
In expressions, when searching by class name, it is better to use the contains function. Details: XPath is powerful!
Here I agree to cookies on the site.
while True:
try:
WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div/div[2]/div/div[3]/button[1]'))).click()
except TimeoutException:
breakDidn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question