Answer the question
In order to leave comments, you need to log in
How to organize the product development process in C++ using GIT?
We have a C++ project for Windows.
Our process is set up like this.
We use svn. A ticket is created in trac, a branch is created for each ticket. When the developer thinks that he has done everything in the branch, I look at the code, if everything looks good, then I merge into the trunk and manually run the functional tests. If everything is ok, then I commit to the trunk. Thus, the trunk is always stable.
I decided to improve the process so that most of the work is done automatically, at the same time switch to git (in which I am not an expert yet, alas).
There will be a development branch and a production branch. The production branch always contains only the code that passed the tests. The production branch is for ongoing development.
I see the process in this way: a ticket is created, then a branch is created (from development), in which the developer works. He writes code and adds tests to test new functionality.
When he considers that the development is completed, he puts the status "Seems to be ready" in the ticket. This tracks a special script that, upon setting the status, will merge the branch into development (but not commit).
If there was a conflict during the merge, then the ticket again goes into the "Open" status.
If everything smerdzhilos, then the code is collected, then the tests are run. If the tests fail, the ticket goes back to the "Open" status.
If the tests passed, then - if there was svn here, then svn commit would be done in development, I don’t know how in git, and the ticket is closed.
This scenario scares me: while the tests are being run, development can change, and there is no guarantee that after the merge, development will remain stable (i.e., the tests pass). After all, we took the old development revision.
Well, I think, in this case, you need to merge and commit it to development, and only then run the tests, but then new branches can be created from the unstable version of development. In addition, while we are running tests for this commit in development, a merge of another branch (or even several!) may arrive in time, and the corresponding test run will show errors in both the first branch and the second, which can be very confusing for everyone. Finally, it's not entirely clear how to roll back if the tests fail.
What is the best way to organize the process?
Answer the question
In order to leave comments, you need to log in
I advise you to look at Git flow (habrahabr)
Git flow (GitHub) to automate routine tasks.
branching model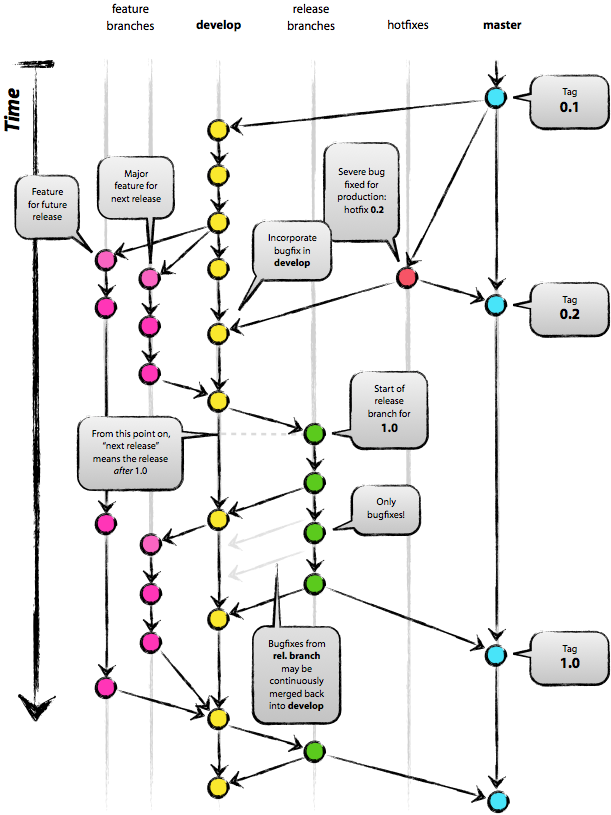
what you are describing is called feature-branch .
your feature branches should always be in sync with the master. All developers should have an up-to-date version of the code they are working with. In this sense, the feature-branch approach, especially when it comes to big changes, can greatly desynchronize the code between developers.
I prefer the Feature Toggle approach as it is more in line with the git philosophy.
Read about the growing Trunk Based Development branching model .
When using this model, you will need a master branch (trunk) and branches for release versions. In master, you are developing (in your terminology, this is development) for each version that goes out to users, you create a separate branch, for example 1.0.x.
Most importantly, all changes are made by developers only to the master branch. Only responsible people can create release branches and push changes from master to them, including when making changes to released versions. Releases
are only built from release branches.
In this model, developers are not limited to creating local branches, but no one wants to see them on a shared server. Developers do not have permission to create branches on a shared server.
The process looks like this:
1. The developer makes a pull master.
2. If necessary, creates a local branch and works in it.
3. Run tests on the branch and merge it with master.
4. Makes a push.
5. CI sees the new commit, gets it, and runs unit, integration, and acceptance tests on it.
I don't really understand why automatic commits might be required, my opinion is that this process should be controlled by people. And the issues in the issue-tracker should be closed by testers or developers if they have written the appropriate tests.
There is nothing wrong with the fact that CI tests will not pass. Basically, that's what he needs. There is no need to roll back the commit, you need to make a new one faster, in which the error is fixed.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question