Answer the question
In order to leave comments, you need to log in
How to make a uniform distribution of surnames in groups?
There is a very unusual and as it turned out quite a difficult problem. Given: list of surnames. It is required to distribute them into letter groups ala A-B in such a way that if there are many surnames starting with A, C, D, E, C, and few for the rest of the letters, then the groups should form A-B, C-D, E- F, Z-C, W-Z. I've been struggling with this for a long time. I just can't think of a normal algorithm... The only thing I've been able to do so far is just scatter them into groups like [ ( 'A' , [ 'Aaaa', 'Abbb', ] ), ]. I will also clarify that the letters coming after the first are unimportant. The main thing is to distribute according to the first letter. Well, I do it in python, but I will be happy with the solution in any language (if, of course, I can understand it: D).
P.S. Here, if it helps, what I could throw. It's certainly not what you need, but I think I'm on the right track...
def distribute(employees):
letters = []
for i in range(ord('А'), ord('Я') + 1):
c = chr(i)
c_employees = [e for e in employees if e[0].upper() == c]
letter = (c, c_employees)
letters.append(letter)
return lettersdef flatten(sequence):
for item in sequence:
if isinstance(item, collections.Iterable) and not isinstance(item, (str, bytes)):
yield from flatten(item)
else:
yield item
def distribute_by_letters(employees):
letters = []
count = 0
for i in range(ord('А'), ord('Я') + 1):
c = chr(i)
c_employees = [e for e in employees if e[0].upper() == c]
letter = (c, c_employees)
letters.append(letter)
if len(c_employees) != 0:
count += 1
avg = len(employees) / count
return (letters, round(avg))
def distribute_by_groups(letters_info):
letters, avg = letters_info
groups = []
i = 0
while i < len(letters):
group_employees = []
j = i
count = 0
while count < avg and j < len(letters):
group_employees.append(letters[j])
count += len(letters[j][1])
j += 1
empty_letters = itertools.takewhile(lambda l: len(l[1]) == 0, letters[j:])
group_employees.extend(list(empty_letters))
begin_letter = letters[i][0]
end_letter = group_employees[-1][0]
group_name = '%s-%s' % (begin_letter, end_letter)
i += len(group_employees)
group_employees = [l[1] for l in group_employees]
group_employees = list(flatten(group_employees))
group = (group_name, group_employees)
groups.append(group)
return groupsAnswer the question
In order to leave comments, you need to log in
Let's say there are 100 people, their last names start with 5 letters i.e. on average, there should be 20 people per letter. We make a cycle with a check if the next letter has less than 20 people, then it can be combined.
For the test, I rolled out a list of the names of all employees (550 people) from the domain directory to the users.txt file.
def chunks(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
#Считываем, убираем дубликаты, сортируем
names = sorted({line.strip() for line in open('users.txt', encoding='utf-8')})
#Разбиваем на примерно равные части и генерируем словарь,
#ключом которого служат первая буква первой и последней фамилии в списке.
catalog = {'{}-{}'.format(item[0][0], item[-1][0]):item for item in chunks(names, 100)}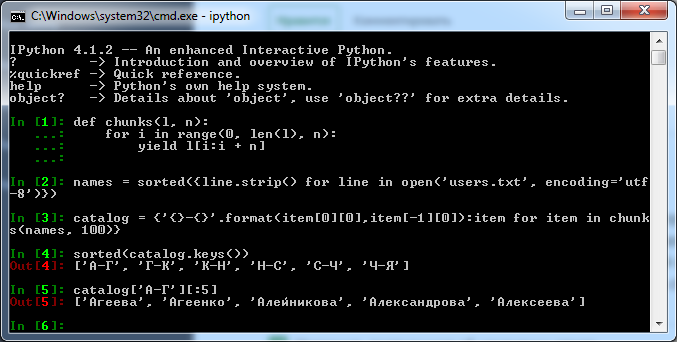
from itertools import groupby
from operator import itemgetter
# Разбиваем на группы по первой букве
def chunks(items):
for letter, names in groupby(sorted(items), key=itemgetter(0)):
yield list(names)
# Сливаем вместе группы меньше min_len в группы не больше max_len
def reshape(items, min_len, max_len):
buffer = []
for item in items:
if len(buffer) >= max_len:
yield sorted(buffer)
buffer = []
if len(item) <= min_len:
buffer += item
else:
yield item
yield sorted(buffer)
#Считываем и сортируем
names = sorted(line.strip() for line in open('users.txt', encoding='utf-8'))
#Разбиваем на примерно равные части
groups_list = reshape(chunks(names), 50, 100)
#генерируем словарь ключом которого служат первая буква первой и последней фамилии в списке
catalog = {'{}-{}'.format(item[0][0], item[-1][0]):item for item in groups_list}Count how many names start with each letter. Then, starting with the letter A, combine the letters until the addition of the next letter causes the group size to go over the boundary of your choice. Starting with this letter, form the next group, so up to the end of the alphabet. The number of groups can be defined as the total number of last names divided by the target group size.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question