Answer the question
In order to leave comments, you need to log in
How to find the greatest common divisor with rounding?
The user taps a short rhythmic pattern of notes of only two durations: xor 2x. About like Morse code, only musically, in tempo. The result is an array of note durations in milliseconds, for example:[145,160,112,170,281,292,258,305,257]
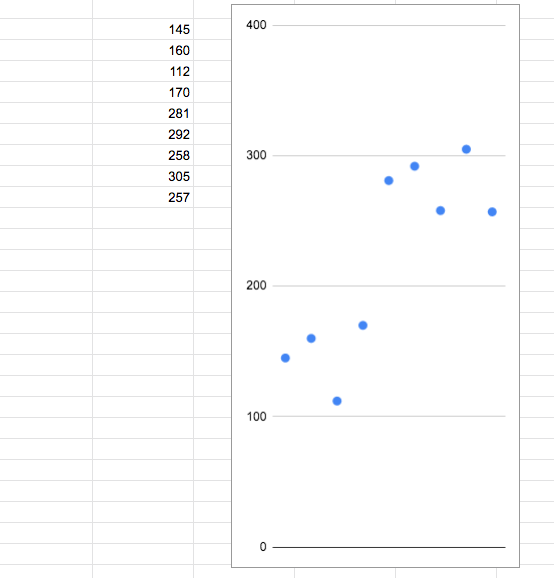
xand "2" for long 2x, so that for the example above it turns out[1,1,1,1,2,2,2,2,2]const a = [145,160,112,170,281,292,258,305,257];
const min = Math.min(...a); // 112
a.map(n => Math.round(n / min)) // [ 1, 1, 1, 2, 3, 3, 2, 3, 2 ]x || 2x. 2xand 3x. Or even more difficult - polyrhythm with rational fractions: 4/4 then at the same pace 6/4 or 5/4. But it's not now. const AB = data => {
const A = [Math.min(...data)];
const B = [Math.max(...data)];
const mean = arr => arr.reduce((a,b) => a + b, 0) / arr.length;
data.forEach(n => {
if (Math.abs(mean(A) - n) <= Math.abs(mean(B) - n))
A.push(n);
else B.push(n);
});
return [A.slice(1), B.slice(1)];
}
AB([145,160,112,170,281,292,258,305,257])
/*
*/Answer the question
In order to leave comments, you need to log in
You can use one of the clustering algorithms in scikit-learn , such as KMeans:
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> notes = [145, 160, 112, 170, 281, 292, 258, 305, 257]
>>> notes = np.array(notes).reshape(-1, 1)
>>> KMeans(n_clusters=2).fit_predict(notes)
array([0, 0, 0, 0, 1, 1, 1, 1, 1], dtype=int32)>>> KMeans(n_clusters=2).fit_predict(notes)
array([1, 1, 1, 1, 0, 0, 0, 0, 0], dtype=int32)Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question