Answer the question
In order to leave comments, you need to log in
How to explain overfitting in terms of signal-to-noise?
How can overfitting be explained in signal-to-noise terms?
Where is the learning-retraining boundary?
Answer the question
In order to leave comments, you need to log in
Generally speaking, in what terms to explain - all the same, because. the overfitting phenomenon is when your model performs well on the training set (well, probably, in your case, it perfectly separates the signal from the noise on the data on which you train it) and poorly, i.e. with a large number of errors - on test data. There is no clear boundary at all. Like much in statistics and machine learning, everything is defined based on common sense and semantics in terms of the applied subject area. Sometimes, however, it is possible to apply "semi-formal" methods, for example, the "knee" method in cluster analysis, but even there the researcher still has the freedom to choose the final solution.
Based on this material , we can say that if there is noise in the objective function that we approximate with our model, then retraining is the fitting of the model to the noise components in the training sample.
If it is assumed that each next stage of model training leads to a decrease in errors on the training set, then the learning-retraining boundary can be the beginning of an increase in errors on the test set (the sample not participating in training).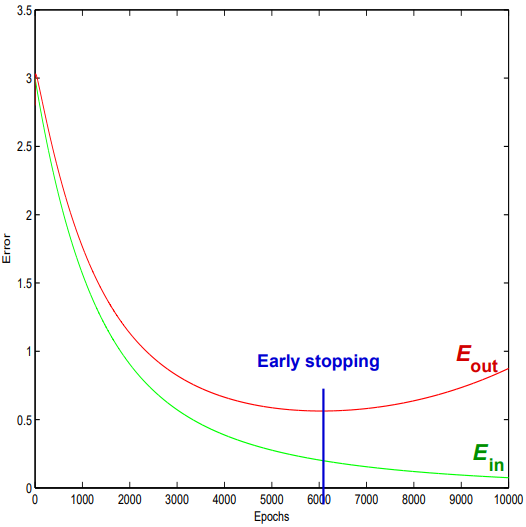
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question