Answer the question
In order to leave comments, you need to log in
Can't parse Google SafeBrowsing, what's wrong?
I wanted to parse https://transparencyreport.google.com/safe-browsin... , a service through which you can check a domain or a link to a ban from Google,
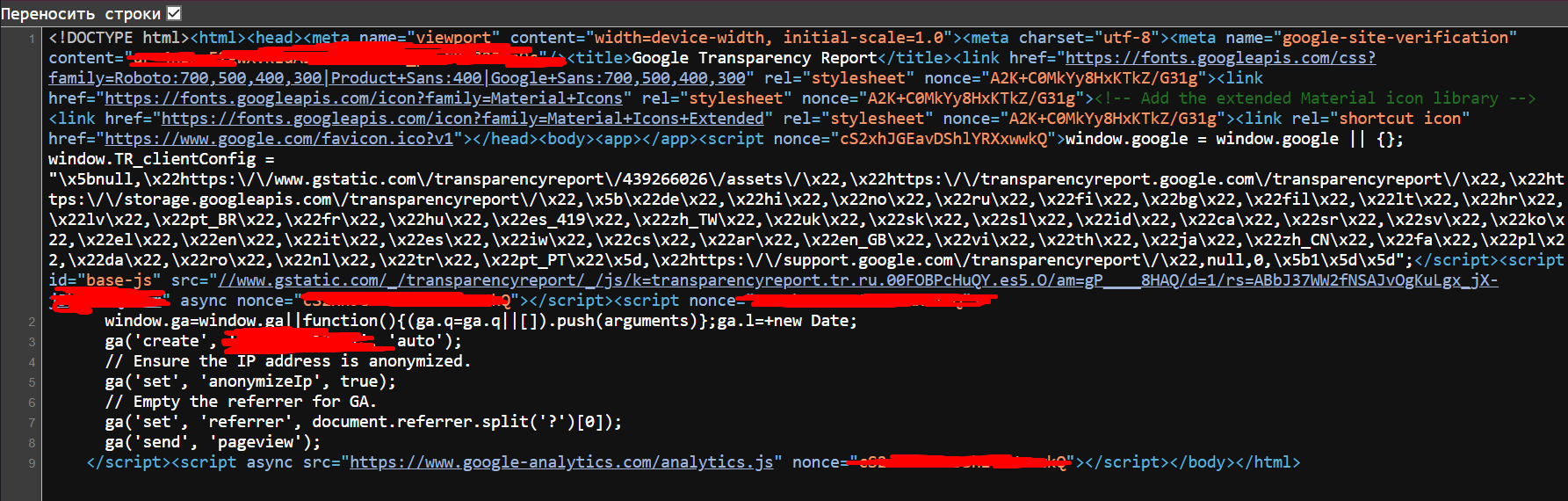
but whatever I did, I got the output "[]", even user-agent added, thinking that I did something wrong, but when I simply displayed all the code through the same script, I got a completely different code, not the one that was during normal inspection, opening the source code in the browser, I understood why, in
other words through inspection one thing, through source code another
import requests
from bs4 import BeautifulSoup
url = 'https://transparencyreport.google.com/safe-browsing/search?url=discord-free.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
}
page = requests.get(url, headers = headers)
soup = BeautifulSoup(page.text, "html.parser")
data = soup.findAll(class_='material-icons ng-star-inserted')
print(data)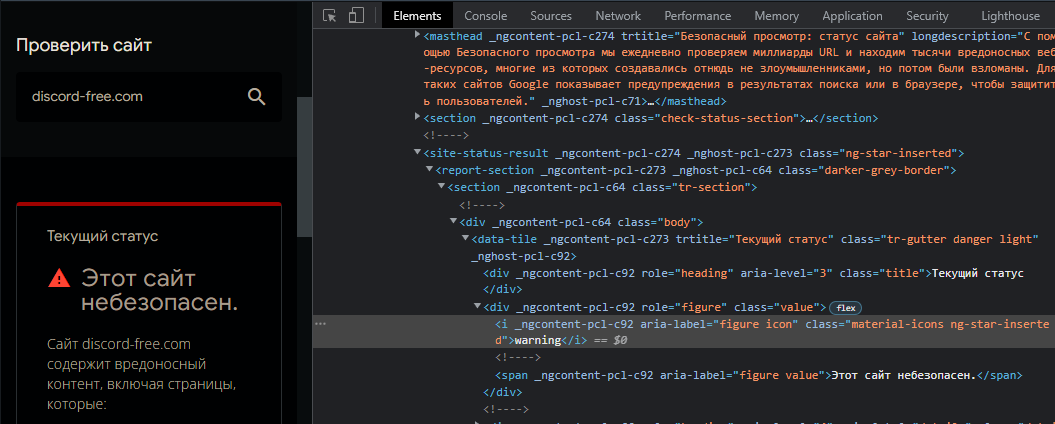

Answer the question
In order to leave comments, you need to log in
because you need to parse to the page, and the XHR request that is executed when the page is loaded
https://transparencyreport.google.com/transparencyreport/api/v3/safebrowsing/status?site=discord-free.comDidn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question