Answer the question
In order to leave comments, you need to log in
Why, when parsing the site, I can not get some text data?
Good day to all professional in my field, I really need your help, I'm trying to parse the page " https://razmerkoles.ru/size/peugeot/308/2013/ "
the problem is to get this data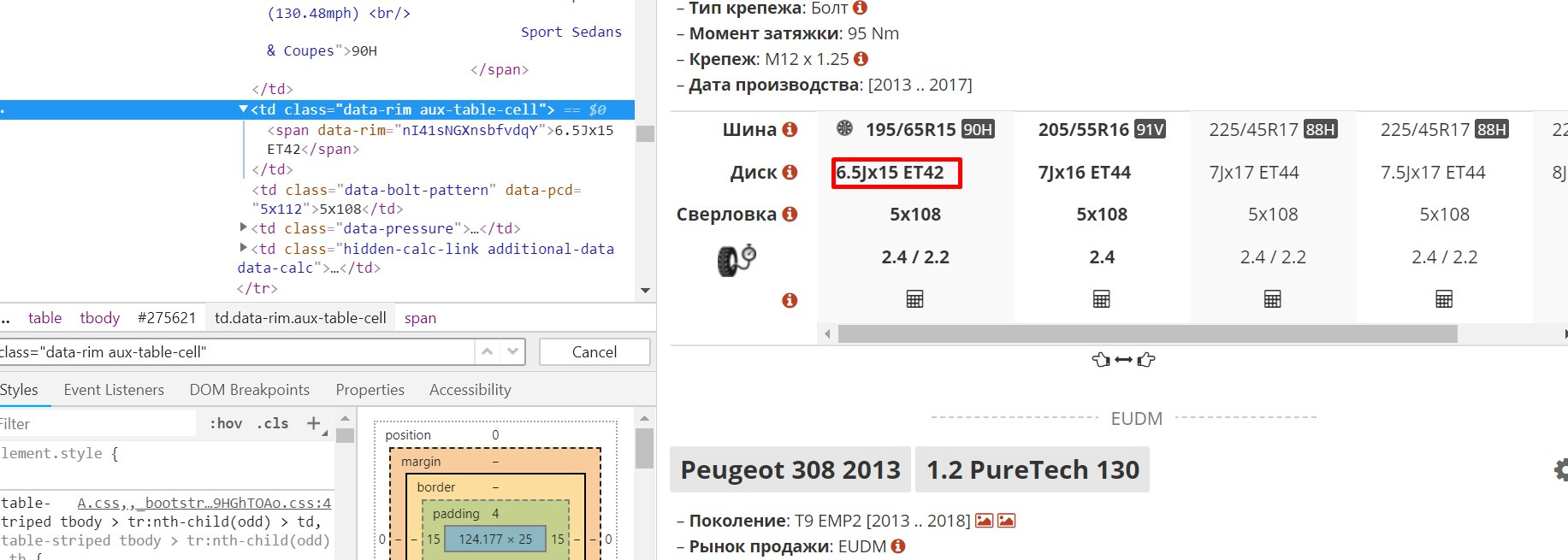
<?php
require_once 'pr-24.12.2018/simple_html_dom.php';
ini_set('memory_limit', '500M');
function getCurlResult ($url) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLPROTO_HTTPS,1);
$htmltext = curl_exec($ch);
curl_close($ch);
//$htmltext = iconv("CP1251", "UTF-8", $htmltext);
return $htmltext;
}
$urlYear = 'https://razmerkoles.ru/size/peugeot/308/2013/';
// print(getCurlResult($urlYear));
// $file = fopen("5.txt", "w");
// fwrite($file, getCurlResult($urlYear));
// fclose($file);
$html3 = str_get_html(getCurlResult($urlYear));
$htmlArr3 = $html3->find('#vehicle-market-data .vehicle-market'); // массив внутренних рынков
if(count($htmlArr3) != 1) {// проверка есть ли разделения на внутренние рынки
foreach ($htmlArr3 as $key => $div) {
// echo $div->outertext . "<br>";
$market = $html3->find('#vehicle-market-data .vehicle-market h4', $key)->plaintext; // выводит название внутреннего рынка
echo $market . "<br>";
foreach ($div->find('.modification-item') as $modifications) { // проходит по модификациям модели на одном рынке // echo "<pre>";
// var_dump($modifications);
// echo "</pre>";
foreach ($modifications->find('tbody tr') as $k => $size) {
// print($size->outertext . "<br>");
$b = $size->find('td[class=data-rim aux-table-cell]')->plaintext;
var_dump($b);
// $file = fopen($k . ".txt", "w");
// fwrite($file, $size->outertext);
// fclose($file);
// $zz++;
// if($zz > 3) {
// exit;
// }
}
}
}
} else { //если нет разделения на внутренние рынки
}
$html3->clear(); // подчищаем за собой
unset($html3);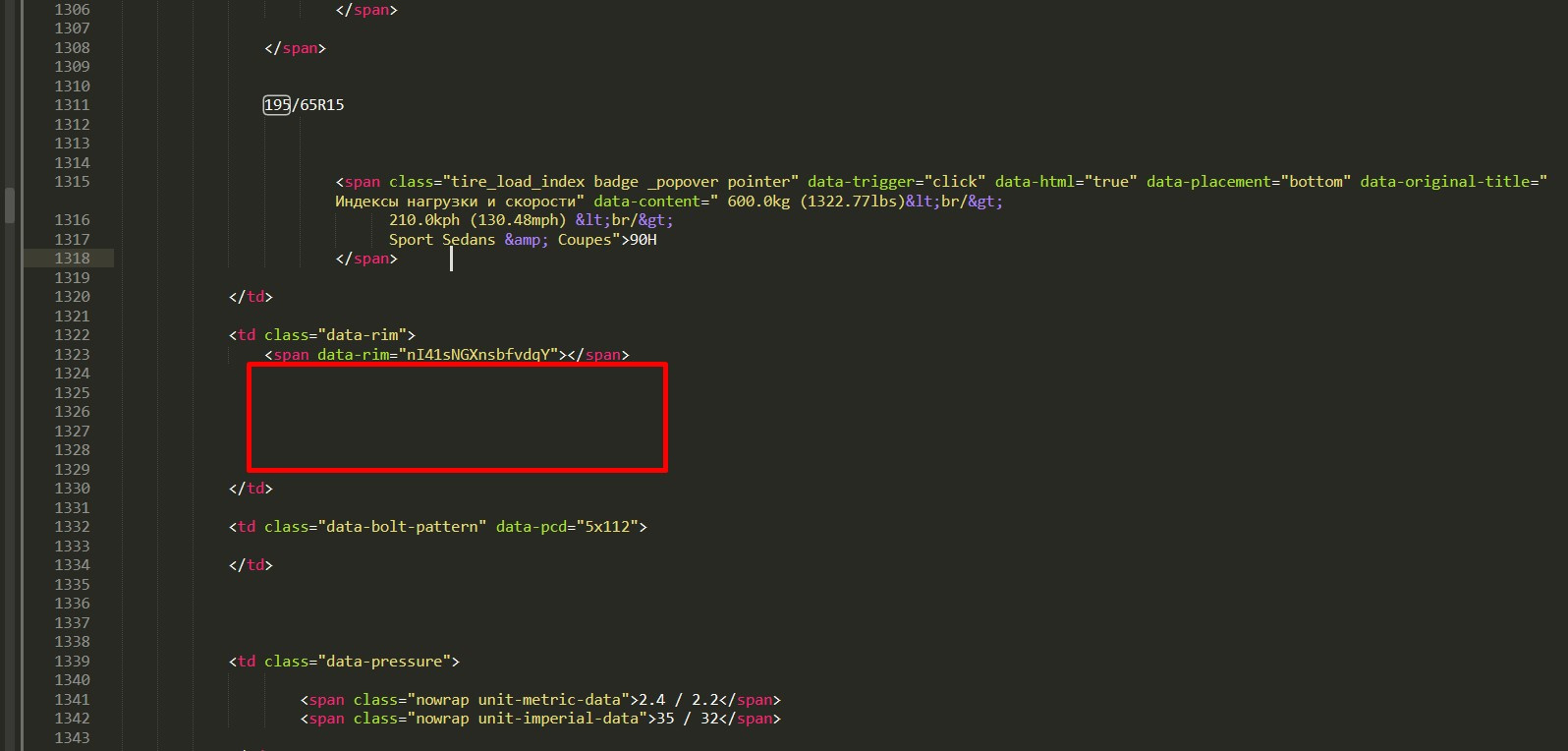
Answer the question
In order to leave comments, you need to log in
An interesting task
Look,
you are interested in the Information block is already here, but first encoded in
base64
,
and
then masked
.
What exactly "all information" do you need? Most likely, it is generated using javascript, so when you "output it to the screen" (to the browser, as I suspect), you see it - js is executed there, but not in curl.
There is protection against parsing, it td[class=data-rim aux-table-cell]is filled through javascript and only with the user agent of a real browser.
<script>
!function () {
(function () {
for (var t = [/PhantomJS/.test(window.navigator.userAgent), /HeadlessChrome/.test(window.navigator.userAgent), navigator.webdriver, window.callPhantom || window._phantom], e = 0; e < t.length; e++) if (t[e]) return !0;
return !1
})() || (function () {
for (var t, e = document.querySelectorAll("span[data-rim]"), r = 0; r < e.length; ++r) {
var n = e[r], a = n.getAttribute("data-rim");
n.innerHTML = (t = a) ? atob(function (t) {
return t.split("").map(function (t) {
return t === t.toUpperCase() ? t.toLowerCase() : t.toUpperCase()
}).join("")
}(t.replace(/-/g, "="))) : t, n.parentNode.classList.add("aux-table-cell")
}
}(), function () {
for (var t = document.querySelectorAll("tbody[data-vehicle]"), e = function (t) {
return String.fromCharCode(t)
}, r = 0; r < t.length; ++r) {
var n = t[r], a = n.getAttribute("data-vehicle");
a = a.match(/\d{3}/g).map(e).join("");
for (var o = n.querySelectorAll("tr>td.data-bolt-pattern"), i = 0; i < o.length; ++i) o[i].innerHTML = a
}
}())
}();
</script>Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question