Answer the question
In order to leave comments, you need to log in
Why is the ODBC driver (SQL Server 2012) returning data in the wrong encoding?
Faced such a problem - there is a remote SQL Server 2012 database, in which there are functions that return data.
The application is deployed in a virtual machine (ubuntu 18.04), the connection is configured via the ODBC driver version 17 (because it was not possible to "negotiate" with the built-in driver):
[email protected]:~$ odbcinst -j
unixODBC 2.3.7
DRIVERS............: /etc/odbcinst.ini
SYSTEM DATA SOURCES: /etc/odbc.ini
FILE DATA SOURCES..: /etc/ODBCDataSources
USER DATA SOURCES..: /home/user/.odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
SQLSETPOSIROW Size.: 8SELECT fld FROM foo.fnBar(123, 'username');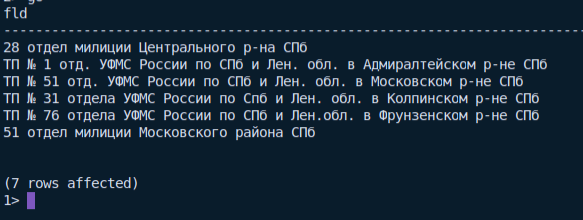



Answer the question
In order to leave comments, you need to log in
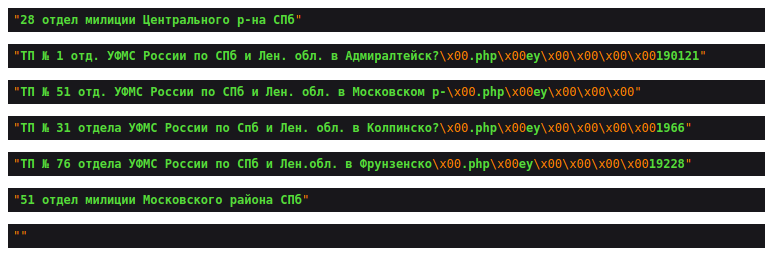
In general, the problem turned out to be in the wrong encoding on the SQL Server side, as it turned out, he still gave cp1251. But the "tails" themselves were still given by the driver, so I had to register when connecting
And run all the answers from the base through my function (I'll leave it here, maybe it will come in handy for someone)
function fixCharset($data, $from = 'cp1251', $to = 'utf8'){
if(is_scalar($data)){
return mb_convert_encoding($data, $to, $from);
}
else {
if ($to_object = is_object($data))
$data = (array)$data;
array_walk_recursive($data, function (&$item, $key) use ($from, $to) {
$item = mb_convert_encoding($item, $to, $from);
});
return $to_object ? (object)$data : $data;
}
}Use the sqlsrv driver to work with the database.
Specify encoding.
Well, you can use mb_ detect _encoding, mb_convert_encoding
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question