Answer the question
In order to leave comments, you need to log in
Why does the parser throw an error?
Guys, the file has been deleted, I'm doing it in haste, my brains are already boiling, help me figure it out.
import requests
from bs4 import BeautifulSoup
HEADERS = {
'User-Agent': 'тут юзер аджент',
'Accept':'тут ассепт'
}
HOST = 'https://www.sravni.ru/bank/sberbank-rossii/'
URL = HOST + 'otzyvy/'
def get_html(url, params = ''):
r = requests.get(url,headers =HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_ ='_227VT')
otzivi = []
for item in items:
otzivi.append(
{
'name': item.find('div', class_='_1tvOC r2Q86').find('div', class_='_3qkdy _7QkVd').find('div', class_='_3bNvn').find('div', class_='_1ubS9 yHpsJ').find('div', class_='_1ubS9 yHpsJ').find('span').get_text()
}
)
return otzivi
html = get_html(URL)
print(get_content(html.text))Answer the question
In order to leave comments, you need to log in
Why shoot yourself in the foot if they give all the reviews in json? Here is a simple code:
import requests
import json
import requests
headers = {
'content-type': 'application/json',
}
data = '''{"filter":{"rated":"Any",
"orderBy":"WithRates",
"tag":"",
"reviewObjectId":276,
"reviewObjectType":"banks",
"page":"1",
"pageSize":20,
"locationRoute":"",
"regionId":"",
"logoTypeUrl":"banks"
}}'''
response = requests.post('https://www.sravni.ru/provider/reviews/list',data=data,headers=headers)
reviews = json.loads(response.text)
total = reviews['total']
print(f'Всего отзывов: {total}')
for review in reviews['items']:
title = review['title']
text = review['text']
print(f'{title} - {text}')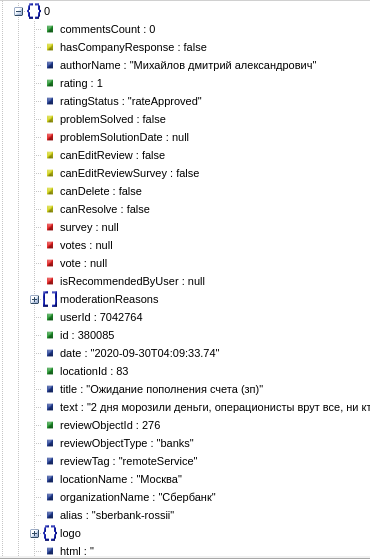
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question