Answer the question
In order to leave comments, you need to log in
What is the best way to organize microservices based on Docker written in node.js?
There is a program or, say, a Cloud service that polls devices using different protocols and receives data from them. Further, it either displays, or archives, analyzes, visualizes, etc. The application runs on AWS services in a compute cluster. All added devices, graphics, etc. organized within the same project. That is, the user logged in, created a project, added a device to the project, and so on.
Each user-created project will run a docker container with a node on it that will poll devices. For example, a user created devices and set the polling rate to 2000 milliseconds. We will get something like
setInterval(function(){
// опрасить устройство
// сохранить данные в базе
}, 2000);Answer the question
In order to leave comments, you need to log in
a container per one task can be expensive even with Fargate. I would stop doing garbage and take AWS StepFunctions with Wait :
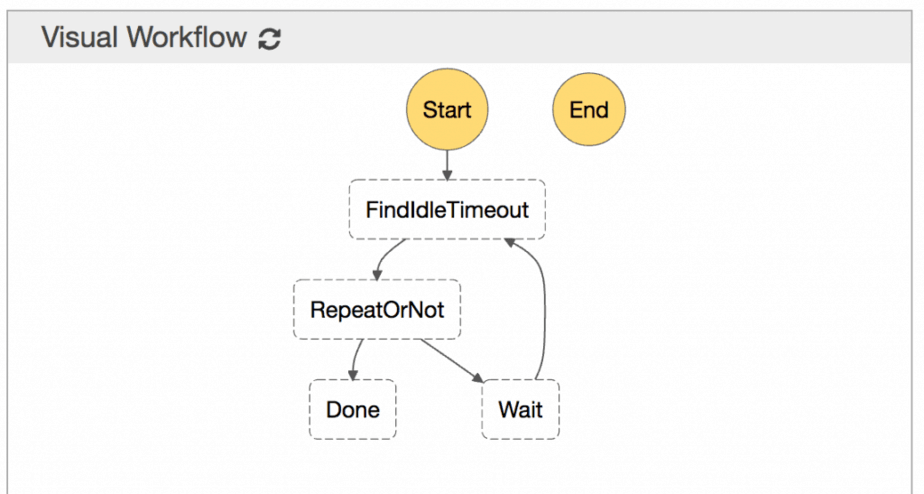
Create a StepFunctions job with parameters and invoke Lambda from it in a loop. Everything, there will be no problems. It is only necessary to take into account that the solution has an execution limit - 1 year, sort of. Next - recreate.
You have to calculate how much it will cost, of course. On Step Functions, one such Job per month can cost about $20 ($10 for SF and $10 for Lambda), without the need for additional management. You can save wherever you want - at least in CloudWatch, at least where you need it.
For comparison, at a minimum on ECS + Fargate it will cost $10 (if there are enough resources), but you need to control somewhere in addition that everything works, the infrastructure and in general. I would pay more for the first option
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question