Answer the question
In order to leave comments, you need to log in
Website parsing, how to bypass protection?
Hello.
When parsing a site from a home PC, it gives out the necessary information, but when I use a server + proxy, each page of the site has the same html page structure, which is why the parser catches the 403 response
Tried different proxies, who can tell me how to get around?
Answer the question
In order to leave comments, you need to log in
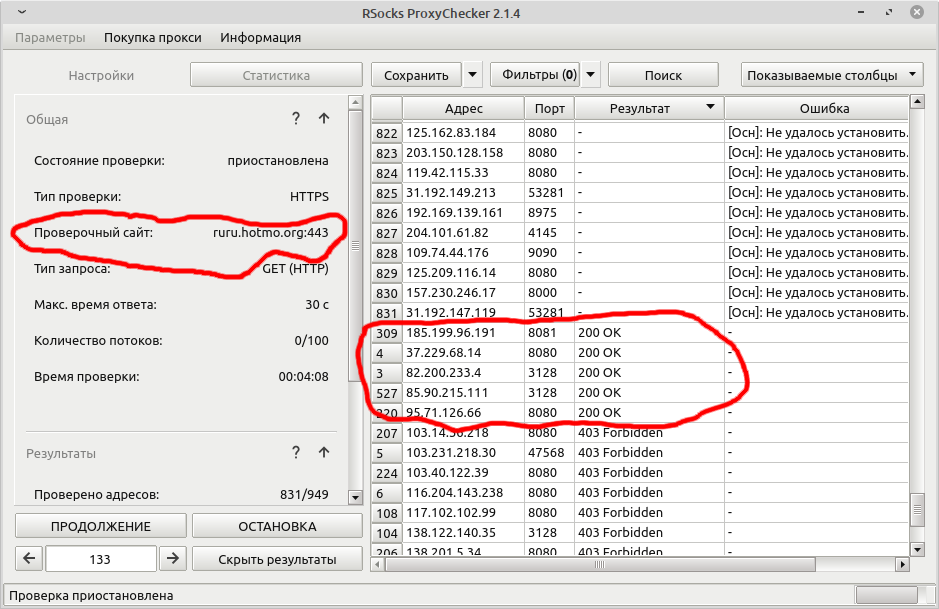
I recommend the program RSocks Proxy Checker There are versions for linux. Upload a list of proxies into it, and specify the site to check 'ruru.hotmo.org'. At the end of the check, sort the results by "200 OK" and save such proxies. Just tested in python, it works.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question