Answer the question
In order to leave comments, you need to log in
Unbalanced Cassandra cluster
Good night, Khabrovites. How are you?
My friend and I are testing a Cassandra cluster of two data centers with five nodes each. We wrote a small script using Faker to fill the cluster with test data. Now there are about 5 million records in the database.
We created the HugeData keyspace using NetworkTopologyStrategy = 3 per DC.

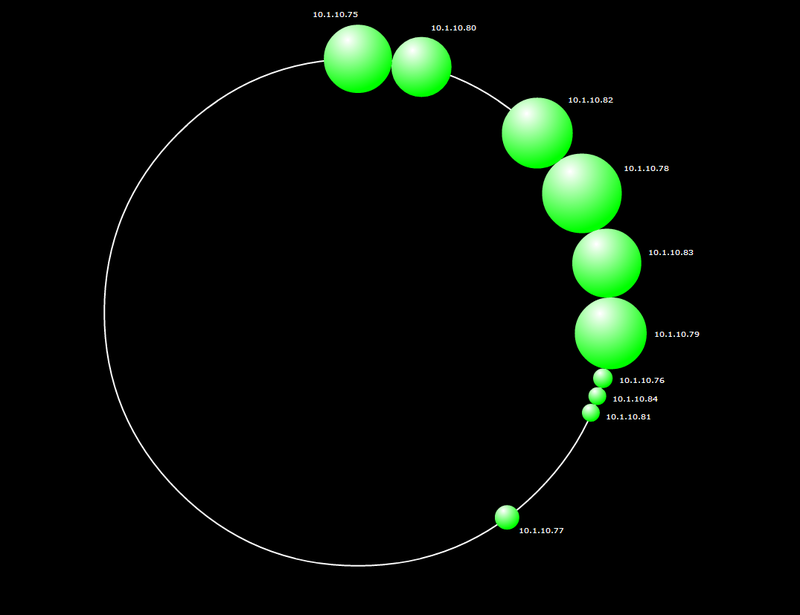
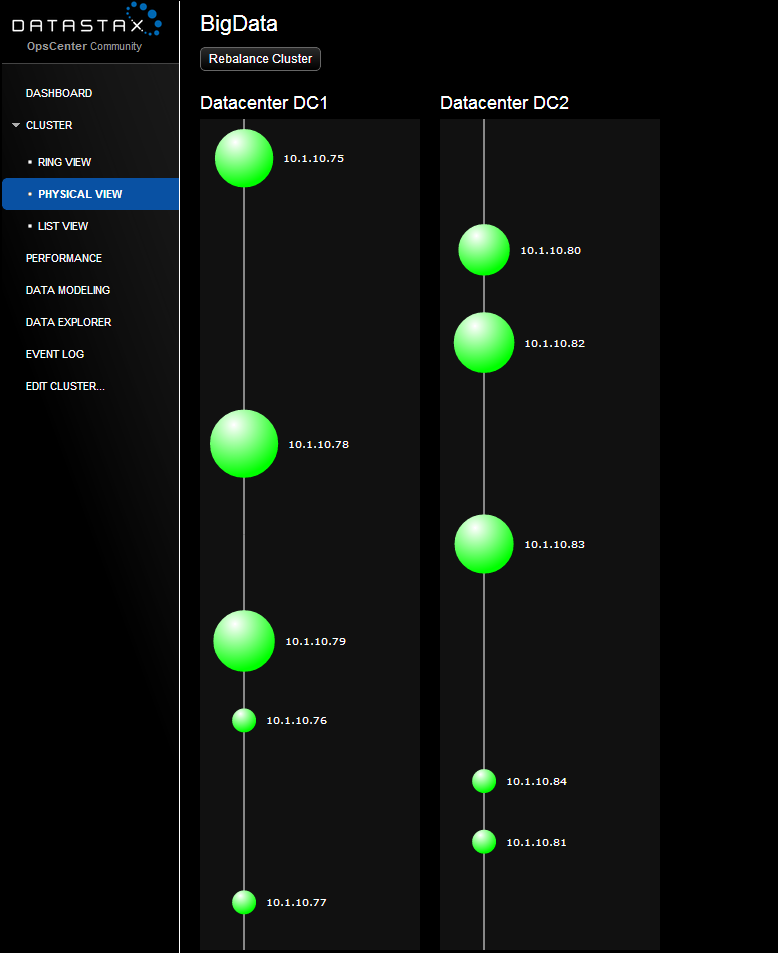
The problem is that we thought that the data would spread evenly over 10 nodes, but the first screenshot shows that only the first 6 are filled with data (it’s understandable, replication factor 3 for each DC).
Perhaps this is due to the fact that the cluster is not balanced? Why did Cassandra score only 6 nodes and not all 10?
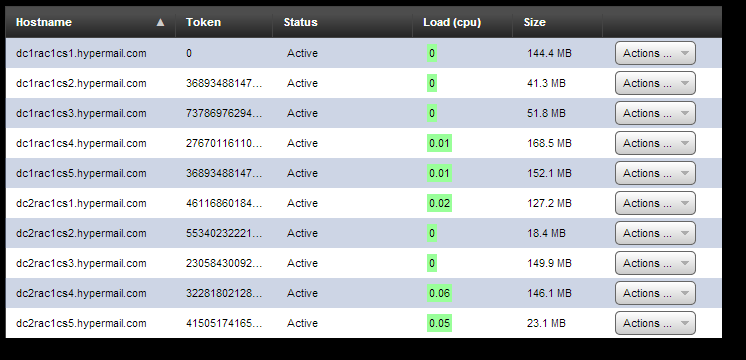
Here is what nodetool satus shows
[[email protected] ~]# nodetool -h 10.1.10.75 status
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Owns Host ID Token Rack
UN 10.1.10.75 144.43 MB 60.0% 9bac71dd-1faf-42c8-a26c-d8fff47abf15 0 RAC1
UN 10.1.10.78 168.48 MB 2.5% c9175995-54dd-4ef2-a4d1-5472d46d8477 2767011611056432740 RAC1
UN 10.1.10.79 152.05 MB 2.5% 69c545ba-716c-4b51-92c1-760063addf00 3689348814741910320 RAC1
UN 10.1.10.76 41.34 MB 0.0% 3d24f678-e3bf-42b0-b4b9-47346e290310 3689348814741910322 RAC1
UN 10.1.10.77 51.81 MB 10.0% 796b196b-6f19-4479-a678-021fa472e107 7378697629483820644 RAC1
Datacenter: DC2
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Owns Host ID Token Rack
UN 10.1.10.80 127.16 MB 2.5% 11b62771-319a-4afd-aeef-40854577d56a 461168601842738790 RAC1
UN 10.1.10.82 149.95 MB 10.0% ee7ddb5e-fe89-4faa-bab6-e5cb33501fd9 2305843009213693950 RAC1
UN 10.1.10.83 146.12 MB 2.5% 7cdc6a59-577f-4b00-a217-c9e5bb5cd77e 3228180212899171530 RAC1
UN 10.1.10.84 23.07 MB 2.5% 64c545c6-e82f-4983-b36b-1bfeed88af1e 4150517416584649110 RAC1
UN 10.1.10.81 18.36 MB 7.5% 0c61d2a2-c255-48fe-b2e3-fac4670c008f 5534023222112865483 RAC1
Answer the question
In order to leave comments, you need to log in
The problem was in the tokens. We had tokens from 0 to +2^63, and since version 1.2 tokens go from -2^63 to +2^63.
We decided to go further and use virtual nodes (appeared in version 1.2), in this case, Cassandra herself arranges the nodes in an optimal way around the ring.
Offer your ideas for benchmarks, I will write an article with the results later.
There is a desire to get to know each other better, in order to satisfy interest in the topic.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question