Answer the question
In order to leave comments, you need to log in
Subquery in ON condition for LEFT JOIN in MySQL
I dug all the stackoverflows and tired google, but I still do not understand why the MySQL query (below) does not work correctly. Please lend a helping hand or throw it in the face of the dock).
Task :
We need to get the latest date from the statistics table for each user.
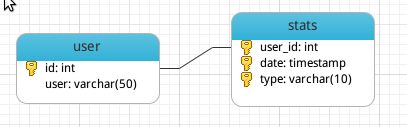
ER diagram (simplified):
SQL query :
SELECT U.*, S.*
FROM `user` AS U
LEFT JOIN stats AS S ON S.user_id = (
SELECT user_id
FROM stats AS S2
# Без этого условия джойнит одну запись, что и нужно. Но, соответственно, ID юзера не соответствует
WHERE S2.user_id = U.id
ORDER BY S2.date DESC
LIMIT 1
)
WHERE U.id = 1
Answer the question
In order to leave comments, you need to log in
As a result, I added a surrogate PK, instead of 3 composite fields. If you do not take into account the denormalization of the database, I think this is the best solution. Final request:
SELECT U.*, S.*
FROM `user` AS U
LEFT JOIN stats AS S
ON S.id = (
SELECT id
FROM stats AS S2
WHERE S2.user_id = U.id
ORDER BY id DESC
LIMIT 1
)
statswith any type (you can specify a specific type) for each user. In this case, sorting by ID will be faster than by date. The record for JOIN is now unambiguous, the situation of selecting several records of statistics with the same date has been resolved. I understand that this is not the answer you are expecting, but if I'm not mistaken, this query will work correctly:
SELECT U.*, S.*
FROM `user` AS U
LEFT JOIN stats AS S
ON S.user_id = u.ID
AND s.date = (
SELECT max(date)
FROM stats AS S2
WHERE s2.user_id = u.id
)
Sorry, maybe I didn't quite understand.
But in my opinion, it is possible somehow easier:
SELECT user.ud, MAX(stats.date) FROM user LEFT JOIN stats ON stats.user_id = user.id
I'd rather do SELECT user_id, MAX(date) FROM stats GROUP BY user_id, and then join users with a query from the application like SELECT * FROM users WHERE user_id IN (...). Something I doubt that four-level queries with subqueries will work quickly, and even in MySQL.
Your request does not work because you select the same user_id from the subquery that you “submitted inside”. In other words, your request is identical to the following:
SELECT U.*, S.*
FROM `user` AS U
LEFT JOIN stats AS S ON S.user_id = U.id
WHERE U.id = 1
SELECT u.*, MAX(s.date) max_date
FROM user u
LEFT JOIN stats s
ON s.user_id = u.id
WHERE u.id = 1
GROUP BY u.id
And if you LIMITremove it, will it connect with all the records? In SQLite, for example, one could use the internal row id without limit, i.e. it would be:
SELECT u.*, s.*
FROM user u
JOIN stat s ON s.rowid = (
SELECT t.rowid
FROM stat t
WHERE t.user_id = u.id
ORDER BY t.date DESC)
WHERE u.id = ?
(SELECT y ...)in the expression it returns the first matched record, and not all; I don't know how with this in MySQL.
If the stats table is a slowly changing dimension and the performance of the request to get up-to-date statistics is important, I would think about other approaches, such as denormalizing stats and storing the actual statistics values in a separate table (or even for the user), while using stats as an audit of changes.
If you don’t like the pattern with creating statistics attributes in the client entity, then try, in the simplest case, to keep one table for actual statistics values with PK [user_id, stat_type] + a table with historical values (audit table), which you will maintain on triggers, if the first is changed.
In an even trickier case, these tables can be combined (as you have now - initially), but to speed up queries, add the current flag, which will be either 1 or NULL + composite index [current, user_id].
The trigger gem from the previous version will be gone, replaced by the current flag accompanying gem.
All sorts of options for organizing such historical reference books with "+" and "-" are described in the Wikipedia article on the topic "slowly changing dimensions".
Ask yourself a question, besides bug traces and rare analytics, is it really important for you to drive requests for obtaining both historical and actual data on one table? If not, the first option is the very thing + partitioning and deleting the oldest partitions on the scheduler (to taste).
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question