Answer the question
In order to leave comments, you need to log in
SQL query. How to find the sum of duplicate rows?
Hello, I'm asking for help.
There is a table table , it has columns id and price.
There are many repetitions in the id field.
Output all ids and their sums of price values, for which the sum of price is greater than 100 from the table table and sorted in descending order.
That is, if there is an id with a value of 10 and it occurs 5 times in the table, then you need to calculate the sum of 5 values of the price field for id with a value of 10 and display this sum as a new summ_price column, which would then leave only rows where the summ_price values are greater than 100 and sort descending.
I hope I explained clearly.
All that has worked so far is:
SELECT id, price, COUNT(*) FROM table GROUP BY id, price HAVING COUNT(*) > 1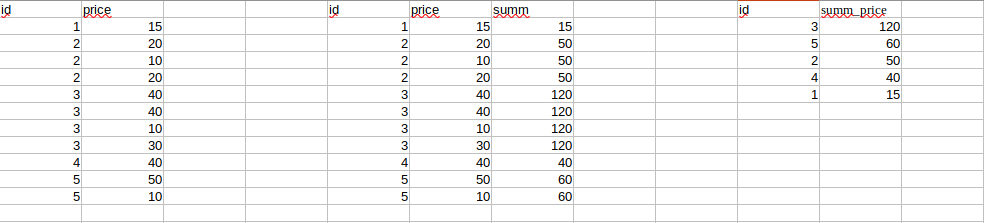
Answer the question
In order to leave comments, you need to log in
Elementary query for summation with grouping:
SELECT id, SUM(price) sum_price
FROM tbl
GROUP BY id
ORDER BY sum_price DESC;Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question