Answer the question
In order to leave comments, you need to log in
Relationship between maximum flow search and Kruskal-Prim algorithm (too much code)?
I wrote a small program to find the minimum spanning tree and (separately) the path with the maximum bandwidth:
// Lab_6.cpp : ąŁč鹊čé čäą░ą╣ą╗ čüąŠą┤ąĄčƹȹĖčé čäčāąĮą║čåąĖčÄ "main". ąŚą┤ąĄčüčī ąĮą░čćąĖąĮą░ąĄčéčüčÅ ąĖ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
//
#include <iostream>
#include <vector>
#include <cstring>
#pragma warning(disable : 4996)
using namespace std;
int main()
{
char data[] = "1-3-6,4-3-2,2-1-4-6-7-8-5,3-1-5-9,4-10-7-3,2-8-3,5-3-8,7-11-3-6,10-4,9-5-11,10-8"; //ą┐ąĄčĆąĄčüčéą░ą▓ą╗ąĄąĮą░ ą╝ąĄčüčéą░ą╝ąĖ 1 ąĖ 2 ą▓ąĄčĆčłąĖąĮčŗ - čüąŠąŠčéą▓ąĄčéčüą▓ąĄąĮąĮąŠ ą▓ą░čĆąĖą░ąĮčéčā - ą┐čāčéčī 2-11
char weight[] = "4-21-7,14-7-4,21-7-21-15-11-9-8,21-14-4-9,4-6-13-8,7-8-15,13-11-13,13-21-9-8,26-9,26-6-15,15-21";//ą┐ąĄčĆąĄčüčéą░ą▓ą╗ąĄąĮą░ ą╝ąĄčüčéą░ą╝ąĖ ą▓ąĄčüą░ ą┤ą╗čÅ 1 ąĖ 2 ą▓ąĄčĆčłąĖąĮ - čüąŠąŠčéą▓ąĄčéčüą▓ąĄąĮąĮąŠ ą▓ą░čĆąĖą░ąĮčéčā - ą┐čāčéčī 2-11
char width[] = "2-20-5,3-4-2,20-4-20-9-8-8,20-3-3-4,3-3-7-8,5-3-4,7-4-3,5-20-8-3,8-4,8-3-9,9-20";//ą┐ąĄčĆąĄčüčéą░ą▓ą╗ąĄąĮą░ ą╝ąĄčüčéą░ą╝ąĖ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┤ą╗čÅ 1 ąĖ 2 ą▓ąĄčĆčłąĖąĮ - čüąŠąŠčéą▓ąĄčéčüą▓ąĄąĮąĮąŠ ą▓ą░čĆąĖą░ąĮčéčā - ą┐čāčéčī 2-11
vector<string> lists;
vector<vector<int>> weight_vec;
vector<vector<int>> width_vec;
vector<vector<int>> vertices;
//ą┐ą░čĆčüąĖąĮą│ čüčéčĆąŠą║ąĖ
//ą┐ą░čĆčüąĖąĮą│ ą▓ąĄčĆčłąĖąĮ
char* pch = strtok(data, ","); // ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čāą║ą░ąĘą░ąĮčŗ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī (ą┐čĆąŠą▒ąĄą╗, ąĘą░ą┐čÅčéą░čÅ, č鹊čćą║ą░, čéąĖčĆąĄ)
while (pch != NULL) // ą┐ąŠą║ą░ ąĄčüčéčī ą╗ąĄą║čüąĄą╝čŗ
{
//std::cout << pch << endl;
lists.push_back(pch);
pch = strtok(NULL, ",");
}
for (auto& i : lists)
{
pch = strtok(const_cast<char*>(i.c_str()), "-");
vector<int> sub_v; // ą┐ąŠą┤čüą┐ąĖčüą║ąĖ ą▓ąĄčĆčłąĖąĮ, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĘą░ą┐čÅč鹊ą╣
while (pch != NULL) // ą┐ąŠą║ą░ ąĄčüčéčī ą╗ąĄą║čüąĄą╝čŗ
{
sub_v.push_back(atoi(pch));
pch = strtok(NULL, "-");
}
vertices.push_back(sub_v);// č乊čĆą╝ąĖčĆčāąĄą╝ ą▓ąĄą║č鹊čĆ čüą┐ąĖčüą║ąŠą▓ ą▓ąĄčĆčłąĖąĮ
}
//ą║ąŠąĮąĄčå ą┐ą░čĆčüąĖąĮą│ą░ ą▓ąĄčĆčłąĖąĮ
lists.clear();
//ą┐ą░čĆčüąĖąĮą│ ą╝ą░čüčüąĖą▓ą░ ą▓ąĄčüąŠą▓
pch = strtok(weight, ","); // ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čāą║ą░ąĘą░ąĮčŗ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī (ą┐čĆąŠą▒ąĄą╗, ąĘą░ą┐čÅčéą░čÅ, č鹊čćą║ą░, čéąĖčĆąĄ)
while (pch != NULL) // ą┐ąŠą║ą░ ąĄčüčéčī ą╗ąĄą║čüąĄą╝čŗ
{
//std::cout << pch << endl;
lists.push_back(pch);
pch = strtok(NULL, ",");
}
for (auto& i : lists)
{
pch = strtok(const_cast<char*>(i.c_str()), "-");
vector<int> sub_v; // ą┐ąŠą┤čüą┐ąĖčüą║ąĖ ą▓ąĄčĆčłąĖąĮ, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĘą░ą┐čÅč鹊ą╣
while (pch != NULL) // ą┐ąŠą║ą░ ąĄčüčéčī ą╗ąĄą║čüąĄą╝čŗ
{
sub_v.push_back(atoi(pch));
pch = strtok(NULL, "-");
}
weight_vec.push_back(sub_v);// č乊čĆą╝ąĖčĆčāąĄą╝ ą▓ąĄą║č鹊čĆ čüą┐ąĖčüą║ąŠą▓ ą▓ąĄčĆčłąĖąĮ
}
lists.clear();
//ą¤ą░čĆčüąĖąĮą│ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┐ąŠč鹊ą║ąŠą▓
pch = strtok(width, ","); // ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čāą║ą░ąĘą░ąĮčŗ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī (ą┐čĆąŠą▒ąĄą╗, ąĘą░ą┐čÅčéą░čÅ, č鹊čćą║ą░, čéąĖčĆąĄ)
while (pch != NULL) // ą┐ąŠą║ą░ ąĄčüčéčī ą╗ąĄą║čüąĄą╝čŗ
{
//std::cout << pch << endl;
lists.push_back(pch);
pch = strtok(NULL, ",");
}
for (auto& i : lists)
{
pch = strtok(const_cast<char*>(i.c_str()), "-");
vector<int> sub_v; // ą┐ąŠą┤čüą┐ąĖčüą║ąĖ ą▓ąĄčĆčłąĖąĮ, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĘą░ą┐čÅč鹊ą╣
while (pch != NULL) // ą┐ąŠą║ą░ ąĄčüčéčī ą╗ąĄą║čüąĄą╝čŗ
{
sub_v.push_back(atoi(pch));
pch = strtok(NULL, "-");
}
width_vec.push_back(sub_v);// č乊čĆą╝ąĖčĆčāąĄą╝ ą▓ąĄą║č鹊čĆ čüą┐ąĖčüą║ąŠą▓ ą▓ąĄčĆčłąĖąĮ
}
//ą║ąŠąĮąĄčå ą┐ą░čĆčüąĖąĮą│ą░
//čüąŠčĆčéąĖčĆąŠą▓ą║ą░ ą▓ąĄčüąŠą▓
for (size_t i = 0; i < weight_vec.size(); i++)
{
for (size_t j = 0; j < weight_vec[i].size(); j++)
{
for (size_t k = 0; k < weight_vec[i].size(); k++)
{
if (weight_vec[i][j] < weight_vec[i][k])
{
swap(weight_vec[i][j], weight_vec[i][k]);
swap(vertices[i][j], vertices[i][k]);
}
}
}
}
// čüąŠčĆčéąĖčĆąŠą▓ą║ą░ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ
/*for (size_t i = 0; i < width_vec.size(); i++)
{
for (size_t j = 0; j < width_vec[i].size(); j++)
{
for (size_t k = 0; k < width_vec[i].size(); k++)
{
if (width_vec[i][j] > width_vec[i][k])
{
swap(width_vec[i][j], width_vec[i][k]);
swap(vertices[i][j], vertices[i][k]);
}
}
}
}*/
int countt = 1;
//ąŠč鹊ą▒čĆą░ąĮąĮčŗąĄ ą▓ąĄčüą░
/*cout << "sorted weights " << endl << endl;
for (auto& i : weight_vec)
{
cout << "vertices " << countt << endl << "--------------------" << endl;
for (auto& j : i)
{
cout << j << endl;
}
cout << endl << "--------------------" << endl;
countt++;
}*/
//ą┤ąŠą╗ą▒ą░ąĮąĮąŠąĄ ąŠčüč鹊ą▓ąĮąŠąĄ ą┤ąĄčĆąĄą▓ąŠ
for (size_t i = 0; i < vertices.size(); i++)
{
for (size_t j = 0; j < vertices[i].size(); j++)
{
int index = 0;
if (vertices[i][j] > 0)
{
index = vertices[i][j] - 1; // ąĖąĮą┤ąĄą║čüąŠą╝ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘ čÅč湥ą╣ą║ąĖ ą▓ąĄą║č鹊čĆą░ (-1 -čé.ą║ ąĮčāą╝ąĄčĆą░čåąĖčÅ čü 0)
}
else if (j < vertices[i].size() - 1 && vertices[i][j + 1] > 0) //ąĄčüą╗ąĖ čāąČąĄ "ąĘą░č鹥čĆą╗ąĖ" ą▓ąĄčĆčłąĖąĮčā - ą┐čĆąŠą▓ąĄčĆčÅąĄą╝ - ą╝čƹȹĄą╝ ą╗ąĖ ą┐ąĄčĆąĄą╣čéąĖ ą║ čüą╗ąĄą┤čāčÄčēąĄą╣
// ąĖ ąĮąĄ "ąĘą░č鹥čĆčéą░" ą╗ąĖ ąŠąĮą░
{
index = vertices[i][j + 1] - 1;
}
else
{
index++; //ąĄčüą╗ąĖ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą▓ąĄą║č鹊čĆąĄ ąĘą░č鹥čĆčéčŗ - ą┐čĆąŠčüč鹊 "ą▓čĆčāčćąĮčāčÄ" ą┤ą▓ąĖą│ą░ąĄą╝čüčÅ ą┤ą░ą╗čīčłąĄ - ąĮąĄ ą┐ąĄčĆąĄą┐čĆčŗą│ąĖą▓ą░čÅ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ
}
int border = 0; // ą│čĆą░ąĮąĖčåą░ čåąĖą║ą╗ą░ ą┤ą╗čÅ čĆą░ąĘąĮąŠą╣ ą┤ą╗ąĖąĮčŗ ą┐ąŠą┤-ą▓ąĄą║č鹊čĆąŠą▓ - čćč鹊 ą▒čŗ ąĮąĄ ą▓čŗą╣čéąĖ ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ ą╝ąĄąĮčīčłąĄą│ąŠ ą▓ąĄą║č鹊čĆą░
bool flag = false;
//ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝, ą║ą░ą║ąŠą╣ ąĖąĘ ą┤ą▓čāčģ ą▓ąĄą║č鹊čĆąŠą▓ ą▒ąŠą╗ąĄąĄ ą║ąŠčĆąŠčéą║ąĖą╣ ąĖ čĆą░ąĘą╝ąĄčĆ ą║ąŠč鹊čĆąŠą│ąŠ čüčéą░ąĮąĄčé ą│čĆą░ąĮąĖčåąĄą╣ ą┤ą╗čÅ čåąĖą║ą╗ą░
if (vertices[index].size() > vertices[i].size())
{
border = vertices[i].size();
}
else
{
border = vertices[index].size();
flag = true;//ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēą░čÅ, ą┤ą╗ąĖąĮą░ ą║ąŠč鹊čĆąŠą│ąŠ ąĖąĘ ą▓ąĄą║č鹊čĆąŠą▓ čüčéą░ą╗ą░ ą│čĆą░ąĮąĖčåąĄą╣ ą╝ą░čüčüąĖą▓ą░ (ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┤ą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ ą┐čĆąŠčģąŠą┤ą░)
}
for (size_t k = 0; k < border; k++)
{
for (size_t t = 0; t < border; t++)
{
if (vertices[index][k] == vertices[i][t] /*|| vertices[index][k] == j + 1*/)
// ąĄčüą╗ąĖ ą╝čŗ ą┐ąĄčĆąĄčłą╗ąĖ ą▓ čāą║ą░ąĘą░ąĮąĮčŗą╣ ąĖąĮą┤ąĄą║čü ąĖ čéą░ą╝ ą▓ čüą┐ąĖčüą║ąĄ ą▓ąĄčĆčłąĖąĮ ąĮą░čłą╗ąĖ čéą░ą║čāčÄ ąČąĄ,
//ą║ą░ą║ ą▓ č鹊ą╝ čüą┐ąĖčüą║ąĄ ąśąŚ ą║ąŠč鹊čĆąŠą│ąŠ ą╝čŗ ą┐ąĄčĆąĄčłą╗čŗ - ąŠą▒čĆą░ąĘčāąĄčéčüčÅ ą┐ąĄčéą╗čÅ - ą┤ą▓ąĄ čĆą░ąĘąĮčŗąĄ ą▓ąĄčĆčłąĖąĮčŗ - čāą║ą░ąĘčŗą▓ą░čÄčé ąĮą░ ąŠą┤ąĮčā
{
vertices[index][k] = -1;// ąĘą░čéąĖčĆą░ąĄą╝ čŹčéčā ą▓ąĄčĆčłąĖąĮčā, ą▓ č鹊ą╝ čüą┐ąĖčüą║ąĄ ąÆ ą║ąŠč鹊čĆčŗą╣ ą┐ąĄčĆąĄčłą╗ąĖ - čĆą░ąĘčĆčŗą▓ą░ąĄą╝ ą┐ąĄčéą╗čÄ
/*vertices[i][k] = -1*/;// ąĘą░čéąĖčĆą░ąĄą╝ čŹčéčā ą▓ąĄčĆčłąĖąĮčā, ą▓ č鹊ą╝ čüą┐ąĖčüą║ąĄ ąśąŚ ą║ąŠč鹊čĆąŠą│ąŠ ą┐ąĄčĆąĄčłą╗ąĖ - čĆą░ąĘčĆčŗą▓ą░ąĄą╝ ą┐ąĄčéą╗čÄ
vertices[i][j] = -1;// ąĘą░čéąĖčĆąĄą░ą╝ čāą┐ąŠą╝ąĖąĮą░ąĮąĖąĄ ąŠ čüąŠčüąĄą┤ąĮąĄą╣ ą▓ąĄčĆčłąĖąĮąĄ - ą║ą░ą║ ąŠ "čüąŠčüąĄą┤ąĮąĄą╣" ą▓ č鹥ą║čāčēąĄą╣ ą▓ąĄčĆčłąĖąĮąĄ, ąŠą▒čĆą░ąĘąŠą▓čŗą▓ą░čłąĄą╣ ą┐ąĄčéą╗čÄ
}
//ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą┐čĆąŠčģąŠą┤ - ą┤ą╗čÅ čüčāą▒-ą▓ąĄą║č鹊čĆąŠą▓ čĆą░ąĘąĮąŠą╣ ą┤ą╗ąĖąĮčŗ, ąĄčüą╗ąĖ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║ąŠąĮčåąĄ ą▒ąŠą╗ąĄąĄ ą┤ą╗ąĖąĮąĮąŠą│ąŠ ą▓ąĄą║č鹊čĆą░
if (flag)
{
int delta = vertices[i].size() - vertices[index].size();
for (size_t d = 0; d < delta; d++)
{
if (vertices[index][k] == vertices[i][t + d] /*|| vertices[index][k] == j + 1*/)
{
vertices[index][k] = -1;
//cout << "OK" << endl;
}
}
}
else
{
int delta = vertices[index].size() - vertices[i].size();
for (size_t d = 0; d < delta; d++)
{
if (vertices[index][k + d] == vertices[i][t] /*|| vertices[index][k] == j + 1*/)
{
vertices[index][k] = -1;
//cout << "OK2" << endl;
}
}
}
//ą║ąŠąĮąĄčå ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ ą┐čĆąŠčģąŠą┤ą░
}
}
}
}
int cnt = 1;
//ąŠč鹊ą▒čĆą░ąĮąĮčŗąĄ ą▓ąĄčĆčłąĖąĮčŗ
cout << "selected vertexes" << endl << endl;
for (auto& i : vertices)
{
cout << "vertices " << cnt << endl << "--------------------" << endl;
for (auto& j : i)
{
cout << j << endl;
}
cout << endl << "--------------------" << endl;
cnt++;
}
}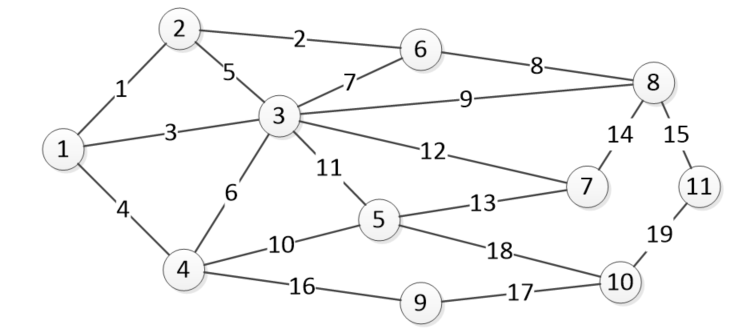
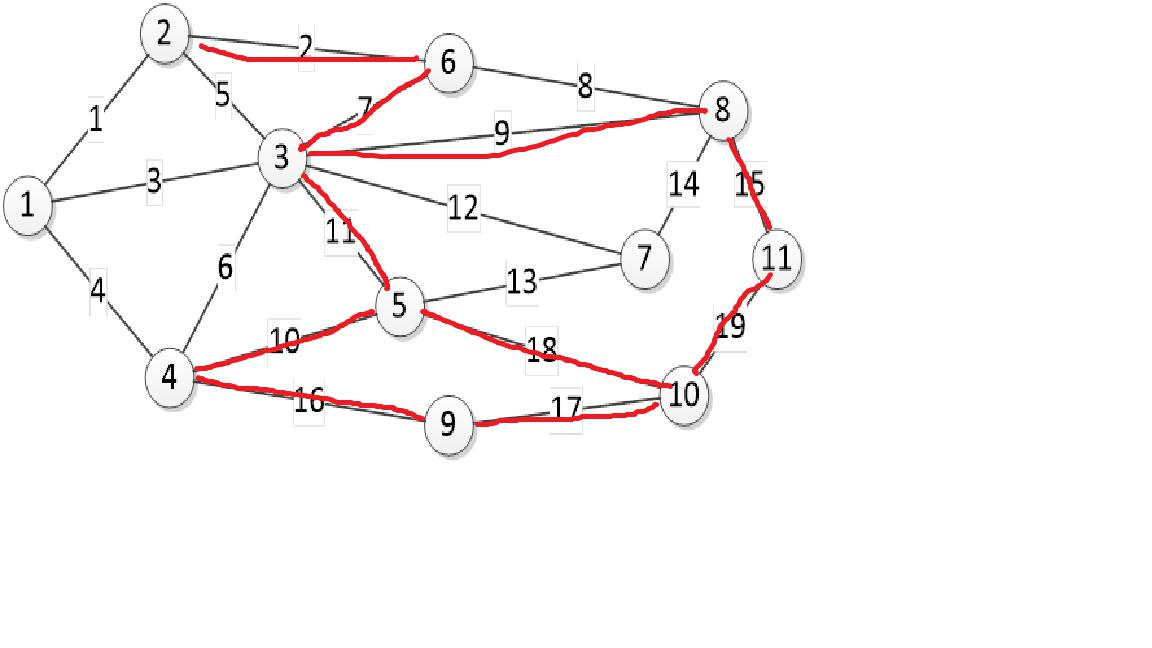 - a case for finding the maximum flow.
- a case for finding the maximum flow. 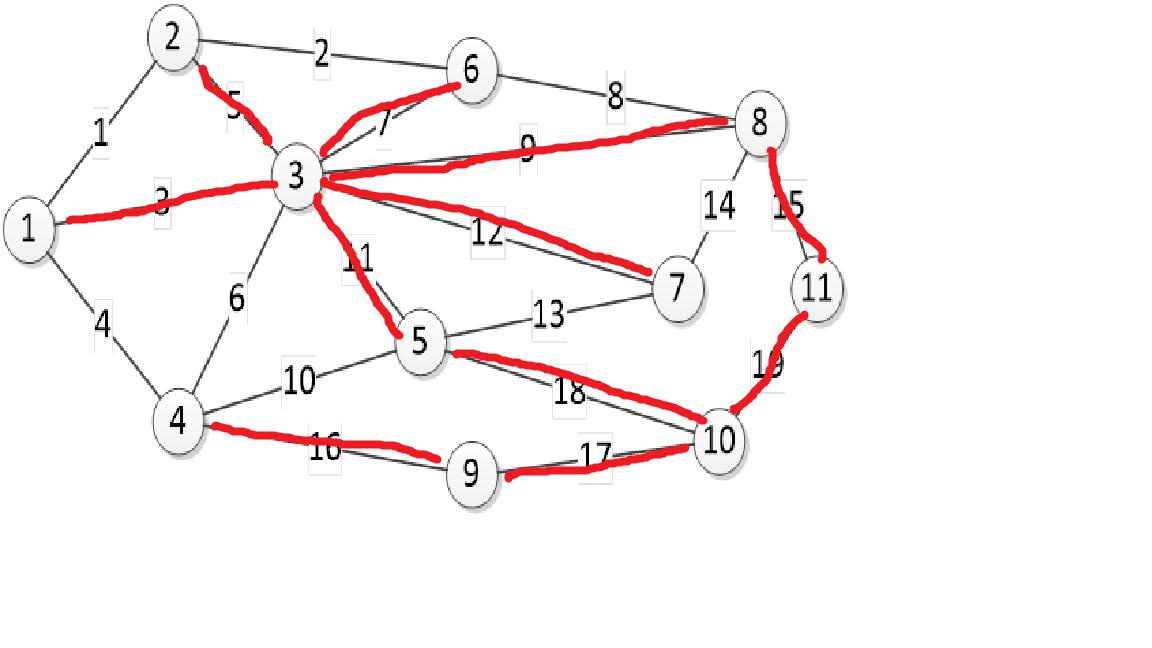
if (vertices[index][k] == vertices[i][t] /*|| vertices[index][k] == j + 1*/)
// ąĄčüą╗ąĖ ą╝čŗ ą┐ąĄčĆąĄčłą╗ąĖ ą▓ čāą║ą░ąĘą░ąĮąĮčŗą╣ ąĖąĮą┤ąĄą║čü ąĖ čéą░ą╝ ą▓ čüą┐ąĖčüą║ąĄ ą▓ąĄčĆčłąĖąĮ ąĮą░čłą╗ąĖ čéą░ą║čāčÄ ąČąĄ,
//ą║ą░ą║ ą▓ č鹊ą╝ čüą┐ąĖčüą║ąĄ ąśąŚ ą║ąŠč鹊čĆąŠą│ąŠ ą╝čŗ ą┐ąĄčĆąĄčłą╗čŗ - ąŠą▒čĆą░ąĘčāąĄčéčüčÅ ą┐ąĄčéą╗čÅ - ą┤ą▓ąĄ čĆą░ąĘąĮčŗąĄ ą▓ąĄčĆčłąĖąĮčŗ - čāą║ą░ąĘčŗą▓ą░čÄčé ąĮą░ ąŠą┤ąĮčā
{
vertices[index][k] = -1;// ąĘą░čéąĖčĆą░ąĄą╝ čŹčéčā ą▓ąĄčĆčłąĖąĮčā, ą▓ č鹊ą╝ čüą┐ąĖčüą║ąĄ ąÆ ą║ąŠč鹊čĆčŗą╣ ą┐ąĄčĆąĄčłą╗ąĖ - čĆą░ąĘčĆčŗą▓ą░ąĄą╝ ą┐ąĄčéą╗čÄ
/*vertices[i][k] = -1*/;// ąĘą░čéąĖčĆą░ąĄą╝ čŹčéčā ą▓ąĄčĆčłąĖąĮčā, ą▓ č鹊ą╝ čüą┐ąĖčüą║ąĄ ąśąŚ ą║ąŠč鹊čĆąŠą│ąŠ ą┐ąĄčĆąĄčłą╗ąĖ - čĆą░ąĘčĆčŗą▓ą░ąĄą╝ ą┐ąĄčéą╗čÄ
vertices[i][j] = -1;// ąĘą░čéąĖčĆąĄą░ą╝ čāą┐ąŠą╝ąĖąĮą░ąĮąĖąĄ ąŠ čüąŠčüąĄą┤ąĮąĄą╣ ą▓ąĄčĆčłąĖąĮąĄ - ą║ą░ą║ ąŠ "čüąŠčüąĄą┤ąĮąĄą╣" ą▓ č鹥ą║čāčēąĄą╣ ą▓ąĄčĆčłąĖąĮąĄ, ąŠą▒čĆą░ąĘąŠą▓čŗą▓ą░čłąĄą╣ ą┐ąĄčéą╗čÄ
}Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question