Answer the question
In order to leave comments, you need to log in
Python requests why is the code not working?
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
url = "https://www.google.com/search?q=%D0%B4%D0%BE%D0%BB%D0%BB%D0%B0%D1%80&oq=%D0%B4%D0%BE%D0%BB%D0%BB%D0%B0%D1%80&aqs=chrome.0.69i59j0i67i131i433j0i67i433j0i67j0i67i433j46i433i512j0i67j0i433i512l2j0i512.6063j0j1&sourceid=chrome&ie=UTF-8"
gd = UserAgent().chrome
print(gd)
response = requests.get(url, headers={'User-Agent': gd})
print(response.status_code)
soup = BeautifulSoup(response.text, "lxml")
print(soup.find("span", {"class": "SwHCTb"}).text)AttributeError: 'NoneType' object has no attribute 'text'Answer the question
In order to leave comments, you need to log in
If find() can't find anything, it returns None:
print(soup.find("nosuchtag"))
# None
You can use this Xpath
//span[text()='Российский рубль']/preceding-sibling::span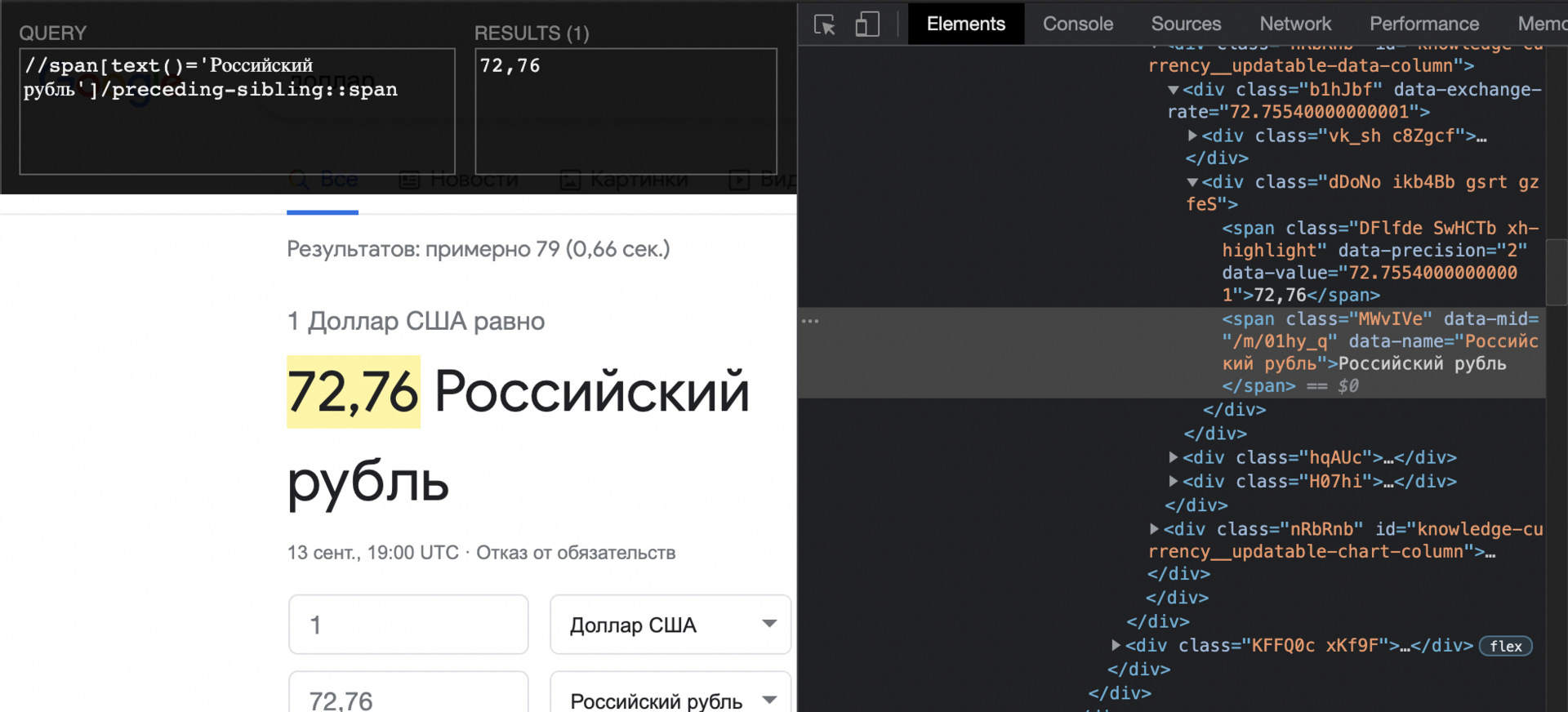
import requests
from fake_useragent import UserAgent
from lxml import etree
url = "https://www.google.com/search?q=%D0%B4%D0%BE%D0%BB%D0%BB%D0%B0%D1%80&oq=" \
"%D0%B4%D0%BE%D0%BB%D0%BB%D0%B0%D1%80&aqs=chrome.0.69i59j0i67i131i433j0i6" \
"7i433j0i67j0i67i433j46i433i512j0i67j0i433i512l2j0i512.6063j0j1&sourceid=chrome&ie=UTF-8"
gd = UserAgent().chrome
response = requests.get(url, headers={'User-Agent': gd})
htmlparser = etree.HTMLParser()
tree = etree.fromstring(response.text, htmlparser)
result = tree.xpath("//div[contains(text(),'Российский рубль')]")
price = result[0].text.split()[0]
print(f'Стоимость доллара: {price} руб.')Стоимость доллара: 72,75
Process finished with exit code 0Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question