Answer the question
In order to leave comments, you need to log in
Need to parse a table from a website?
Hello! I'm a novice programmer and I need to parse a table from the site --> https://opi.dfo.kz/p/ru/DfoObjects/objects/teaser-...
To be honest, I don't understand how to parse it, I've been scratching my head for 3 hours, please help me figure it out, otherwise I myself won’t be able to understand what to do here, I googled how others do it, but the explosion of the brain.
Answer the question
In order to leave comments, you need to log in
import requests
from bs4 import BeautifulSoup
from lxml import html
import csv
headers = {'user-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
url = 'https://opi.dfo.kz/p/ru/DfoObjects/objects/teaser-view/25720?RevisionId=0&ReportNodeId=2147483637&PluginId=6c2aa36248f44fd7ae888cb43817d49f&ReportId=61005620'
response = requests.get(url,headers=headers)
file = open('data.csv','w') # Открываем файл на запись. Можно было использовать контекстный менеджер, но так думаю проще.
writer = csv.writer(file) # Передаем в функцию writer дескриптор открытого файла.
soup = BeautifulSoup(response.text,"html.parser")
rows = soup.find('table',class_='dsnode-table').find('tbody').find_all('tr') # Ищем в html тег 'table' с классом 'dsnode-table',
# далее в найденом ищем тег 'tbody' и наконец ищем все теги 'tr'. Тег 'tr' в html это тег строки таблицы. В результате, в rows
# у нас окажутся все теги 'tr', тоесть все строки таблицы.
for row in rows: # Проходимся по всем строкам. При каждой итерации, в row у нас будет следующая строка таблицы, вместе с html тегами.
columns = row.find_all('td') # Ищем в текущей строке таблици все теги 'td'. В html td - это тег ячейки.
data_list = [columns[0].text,columns[1].text,columns[2].text,columns[3].text,columns[4].text,columns[5].text,columns[6].text,columns[7].text,columns[8].text]
# Так как в каждой строке 9 ячеек, а элементы списка в большинстве ЯП нумеруюются с нуля, то мы можем обратится к конкретной ячейке
# текущей строки по индексу. Первая ячейка будет columns[0], а последняя, тоесть девятая - columns[8]. Создаем список 'data_list',
# и заносим в него все ячейки текущей строки. Но, так как в columns кроме текстовых данных также присутствуют html теги, мы обращаемся
# к свойству .text, что-бы получить сам текст, без тегов.
writer.writerow(data_list) # Записываем текущую строку в csv файл.
# Далее цикл продолжается, пока не достигнет конца таблицы(условно, так как все строки таблици мы уже получили, и они хранятся в 'rows')
file.close() # Так как мы не используем контекстный менеджер with, обязательно закрываем открытый файл.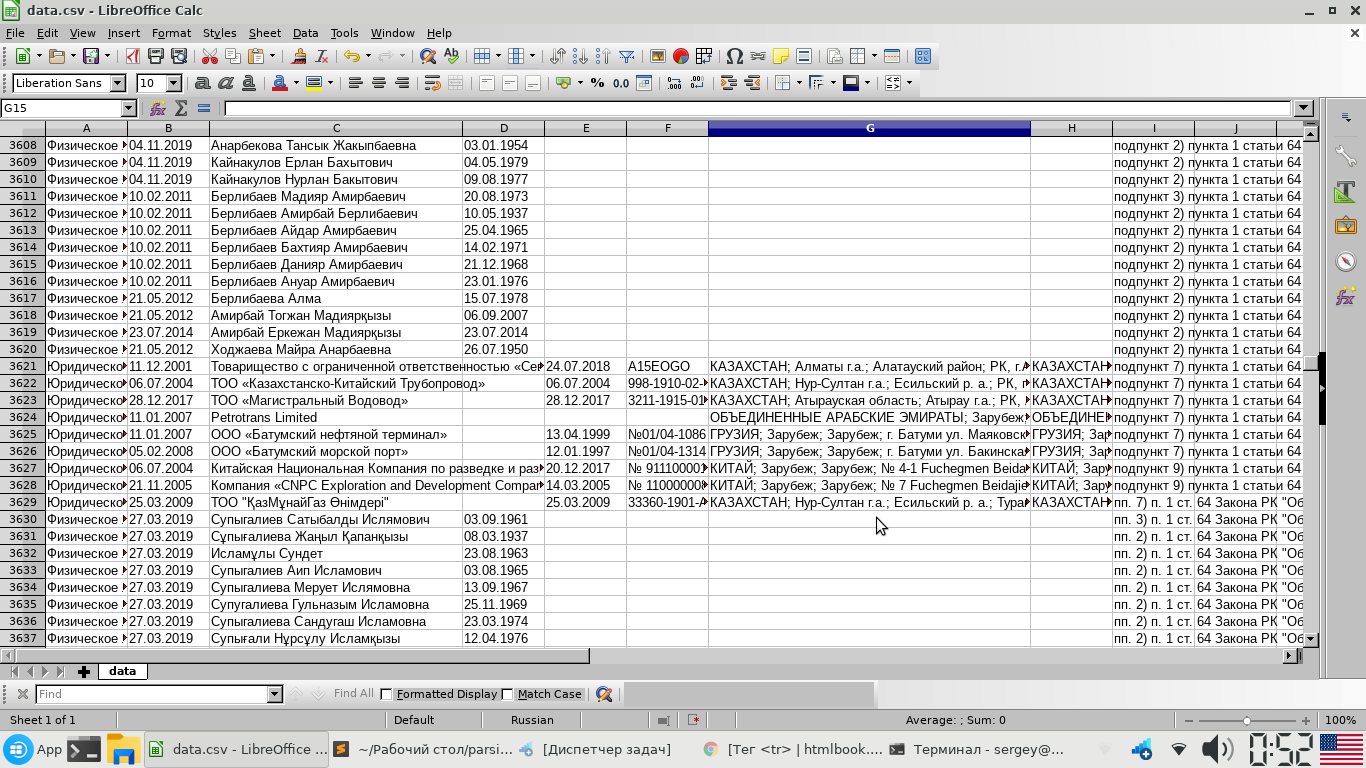
It turns out something like this
import json
import requests
from bs4 import BeautifulSoup
URL = 'https://opi.dfo.kz/p/ru/DfoObjects/objects/teaser-view/25720?RevisionId=0&ReportNodeId=2147483637&PluginId=6c2aa36248f44fd7ae888cb43817d49f&ReportId=61005620'
HEADERS = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0',
'accept': '*/*'}
def get_html(url, params=None):
# Получение объекта Response
r = requests.get(url, headers=HEADERS, params=params)
return r
def get_content(html):
# Получение объекта BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# Парсинг название заголовков
table_headers = tuple(map(lambda elem: elem.get_text(strip=True), soup.select('table.dsnode-table thead tr td')))
# Пасринг строк таблицы
table_strings = tuple(map(lambda elem: elem, soup.select('table.dsnode-table tbody tr')))
# Компоновка информации в массив словарей
table = [{header: element_table.get_text(strip=True) for header, element_table in
zip(table_headers, string.select('td'))} for string in table_strings]
return table
def parse():
html = get_html(URL.strip())
# Проверка на получение успешного ответа с сервера
if html.ok:
try:
data = get_content(html.text)
write_to_file(data)
except Exception as ex:
print(ex)
else:
print('Error connection')
def write_to_file(data):
with open(f"{input('Введите название файла: ')}.json", "w", encoding="utf-8") as write_file:
json.dump(data, write_file, ensure_ascii=False, indent=4)
parse()Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question