Answer the question
In order to leave comments, you need to log in
Link parsing problem?
I am making a music parser from the site: https://sefon.pro, when I try to parse a link to download music, it is displayed in incomprehensible characters.
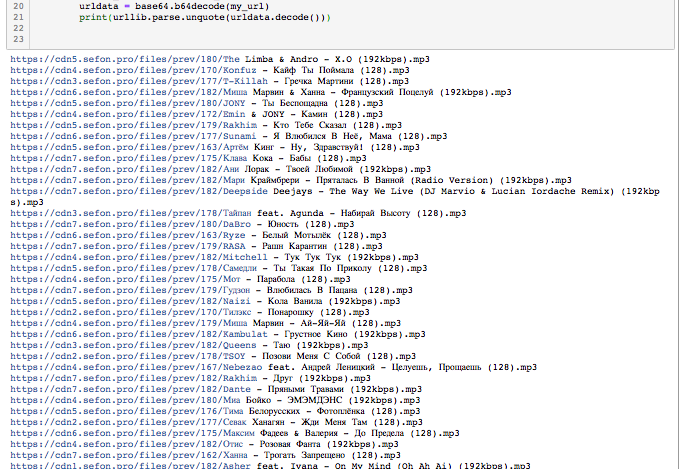
The site is a link looks like this: https: //cdn6.sefon.pro/files/prev/180/The%20Limba% ...
After parsing like this: # MmticHMlMjkubXAz1aHR9UaGUlMjBMaW0cHM4MC9maWxlcy9uLnByby9LnNlZm2jZG4Ly9wcmV6LzE50iYSUyMCUyNiUyMEFuZHJvJTIwLSUyMFguTyUyMCU
yODE
I had clambered all Google and so have not found a solution this problem.
Here is the actual code that I did the parsing:
from bs4 import BeautifulSoup as BS
import urllib.request
def parse_music(name=''):
if name == "":
site = requests.get("https://sefon.pro/best/" + str(name))
else:
site = requests.get("https://sefon.pro/search/?q=" + str(name))
html = BS(site.content, 'html.parser')
music_list = []
for el in html.select(".mp3"):
music = el.select(".btns > a")
print(music)
for ell in music:
music_list.append({
'track_url' : ell.get("data-url")
})
print(music_list[0])
parse_music()Answer the question
In order to leave comments, you need to log in
It looks like base64
>>> import base64
>>> base64.b64decode('MmticHMlMjkubXAz1aHR9UaGUlMjBMaW0cHM4MC9maWxlcy9uLnByby9LnNlZm2jZG4Ly9wcmV6LzE50iYSUyMCUyNiUyMEFuZHJvJTIwLSUyMFguTyUyMCU')
b'2kbps%29.mp3\xd5\xa1\xd1\xf5F\x86RS#\x04\xc6\x96\xd1\xc1\xcc\xe0\xc0\xbd\x99\xa5\xb1\x95\xcc\xbd\xb8\xb9\xc1\xc9\xbc\xbd.sefm\xa3dn\x0b\xcb\xdc\x1c\x99^\x8b\xccNt\x89\x84\x94\xc8\xc0\x94\xc8\xd8\x94\xc8\xc1\x05\xb9\x91\xc9\xbc\x94\xc8\xc0\xb4\x94\xc8\xc1`\xb9<\x94\xc8\xc0\x94'I've already googled all over and still haven't found a solution to this problem.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question