Answer the question
In order to leave comments, you need to log in
Is tesseract not working correctly?
I need to recognize numbers and letters in pictures. I decided to use tesseract. But due to some difficulties with recognition, I decided to crop the photo and recognize only the areas I needed. I wrote a code that did this using Pillow. But then something strange began. When cropping a photo with 'hands' using the forces of Windows, everything is super recognized. But when recognizing an image clipped by the code, tesseract from 10 recognitions never even came close to the previous result. Maybe someone faced such a problem? Or maybe someone knows how to crop a photo without Pillow? Since I found tutorials only for this library. Next comes the code that crops the photo.
import re
from PIL import Image
def crop(image_path, coords, saved_location):
image_obj = Image.open(image_path)
cropped_image = image_obj.crop(coords)
cropped_image.save(saved_location)
cropped_image.show()
addres = (627, 541, 906, 631)
if __name__ == '__main__':
image = 'image/shot_003 (2).jpg'
crop(image, addres, 'image/shot_001.jpg')
Answer the question
In order to leave comments, you need to log in
I'm using OpenCV for photo cropping. I tried it on your photo - everything works even without conversion on the picture
image = cv2.imread(FILE)
cropped = image[10:40, 0:80]
result = pytesseract.image_to_string(cropped)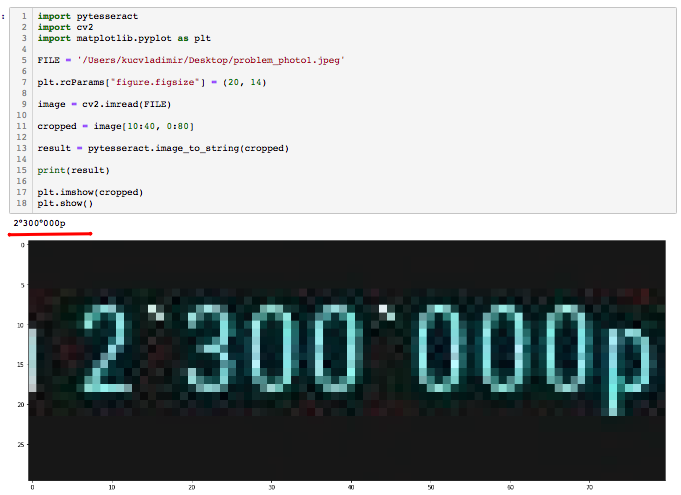
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question