Answer the question
In order to leave comments, you need to log in
How would you implement computing a list of the user's "favorite emoji"?
Hello, friends.
In a chat input, it's useful to have a line with the user's favorite emoji. It looks like this:
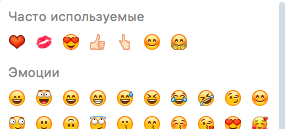
How it is implemented now, I have
0. To store the user's favorite emoji, we use a separate small table:
CREATE TABLE top_used_emojis (
user_id BIGINT PRIMARY KEY,
emojis TEXT[] NOT NULL
);CREATE TABLE chat_messages (
user_id BIGINT NOT NULL,
text TEXT,
...
)CREATE INDEX chat_messages_text_index ON chat_messages (text);user_id, calculates the top 10 most common emoji in the user's message texts, and stores the result in a emojistable field top_used_emojisby the key user_id. CREATE TABLE emojis (
emoji TEXT PRIMARY KEY /* Здесь лежит сама эмодзи */
);CREATE OR REPLACE FUNCTION updateTopUsedEmojis (BIGINT) RETURNS TEXT[] AS '
DECLARE
_user_id ALIAS FOR $1;
query_result TEXT[];
BEGIN
WITH last_top_used AS (SELECT emoji, count(*)::INT AS count
FROM chat_messages cm
JOIN emojis e
ON (cm.text LIKE ''%'' || e.emoji || ''%'')
WHERE cm.user_id = _user_id
GROUP BY e.emoji
ORDER BY count DESC
LIMIT 10)
INSERT INTO top_used_emojis (user_id, emojis)
VALUES ( _user_id,
(SELECT array_agg(emoji) FROM last_top_used)::TEXT[]
)
ON CONFLICT (user_id)
DO UPDATE
SET emojis = (SELECT array_agg(emoji) FROM last_top_used)::TEXT[]
RETURNING emojis::TEXT[]
INTO query_result;
RETURN query_result;
END;
'LANGUAGE plpgsql;FROM chat_messages cm
JOIN emojis e
ON (cm.text LIKE '%' || e.emoji || '%')emojiswith lines in advance '%...%'?LIKEthere. Whether there are more productive decisions?Answer the question
In order to leave comments, you need to log in
I would make a field in the top_used_emojis table that stores the number of uses of each intersection of user with emoji and put an index on this field DESC and in Primary I would shove the user_id and emoji fields together.
I would hang triggers on the chat_messages table to recalculate the number in top_used_emojis
Well, I would display it with a simple ORDER BY on an index with a limit
Let the user choose their favorite emoji. Zadolbali your algorithms, knowing better than me what I need.
Isn't it better to store them in one field in JSON? For example, make two fields - mostUsed (the most frequently used) and recentlyUsed (the last used ones, so that new used emojis can get into mostUsed based on this data). IMHO for such functionality it is not necessary to start a separate table.
PS And of course, store the number (or better, the frequency of occurrence) of use cases, in order to either add to mostUsed, or remove it from there in favor of emoji from recentlyUsed.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question