Answer the question
In order to leave comments, you need to log in
How to use Python to find all the mentioned cities and streets in a multitude of docx documents?
Hello.
There are about 40 format documents (.docx). In these documents, there is a mention of cities and streets, the format "Moscow, Lenina st. 40" and so on. The cities in the documents are different, there can be several cities in one document. Each document consists of 20-30 pages of text.
It is required to pull out from all these documents exactly the city, street and house number, and then put all this data into an excel table with columns:
1) Ordinal number
2) City
3) Street, house number
4) Path to the file where this city was found , street, house
For example, this is how the text looks like in the original version and you need to pull out exactly this

-
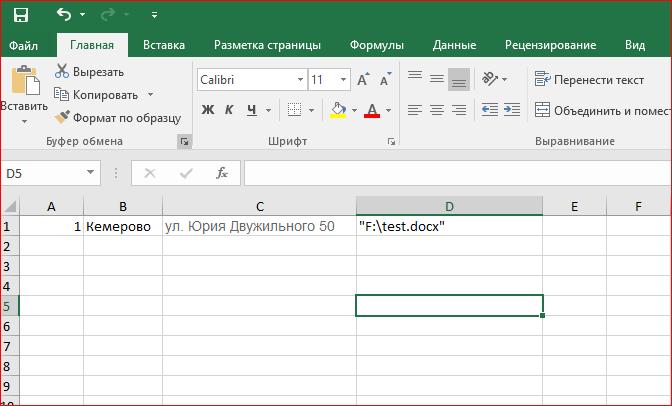
Please help me and give me an idea how to do it. I will be very grateful.
Answer the question
In order to leave comments, you need to log in
Concerning text processing, the question is solved. Regarding the insertion into excel, I think no one will have problems.
Here are a couple of links to articles that helped me write a regex -
The very same regex that I got looks like this
(г|снт|п)(\.|\,|\s)(\s|\.|.|\D*|\D*\,|\D*.|\D*\s\-|\w*|\W*)(ул|пер|б-р|просп|пр-кт|пр)(\.|\,|\s)(\D*\s|\D*\,|\D*.|\D*\s\-)([\d*\s]{1,3})Your question is quite extensive:
1. Select text from docx
2. Process text and get addresses
3. Paste into Excel
I will focus on the part that, in my opinion, causes the most difficulty - at the second stage, for the rest - the answer is easily found.
Pull out the text from the document
Next, pull out with regular expressions what you need
. For example, I sketched it in haste. You can add variations:
regexp = "((г|город|пгт|ст|с)(\.|\s)\w+,.*(ул|улица|пр|проспект|проулок|проезд)(\.|\s).*?\d+?)\D+"
address = re.findall(regexp, str1, re.IGNORECASE)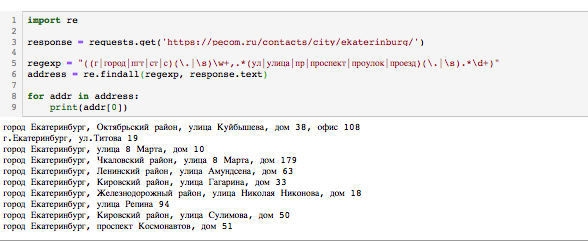
1. We read the text pip install python-docx
2. we write a regular expression to find the desired substring. this is the trickiest part. here you need to look at the structure of documents, if there are some general patterns like "present ..." or "city * street * street numbers" then you need to cling to them in the regular season. also, for verification, you can check the values found by the regular expression, with the list of cities, to check the correctness of the result.
only it needs to be pulled somewhere beforehand)
3. we write in excel pip install openpyxl
All this in a cycle for one document, and the second level of the cycle - for paragraphs in the document.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question