Answer the question
In order to leave comments, you need to log in
How to turn what returns WM_CHAR into unicode?
There is WndProc and it has WM_CHAR processing.
Only if you translate the character code that it gives out, it will be a krakozyavra. (this is if the Russian layout) 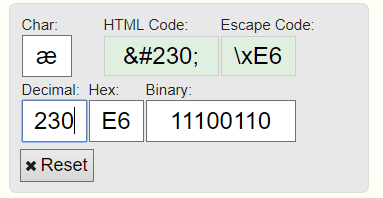
And the code of Russian letters generally starts with 1k. 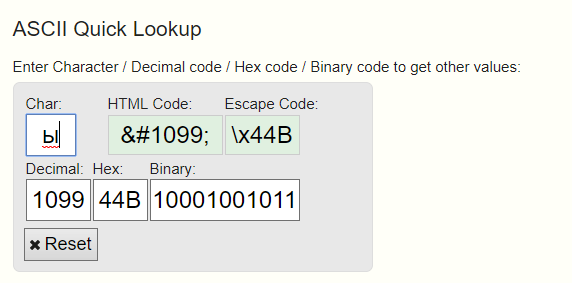
How to fix it?
Answer the question
In order to leave comments, you need to log in
Recardo_Recoly ,
I see.
1. It is better to use WM_UNICHAR, it also works with codes over 65535. At least WinXP is supported.
2. How to turn a code position into UTF-8, there are many options. I'll find mine now.
enum {
SURROGATE_MIN = 0xD800,
SURROGATE_MAX = 0xDFFF,
SURROGATE_LO_MIN = SURROGATE_MIN,
SURROGATE_HI_MIN = 0xDC00,
SURROGATE_LO_MAX = SURROGATE_HI_MIN - 1,
SURROGATE_HI_MAX = SURROGATE_MAX,
UNICODE_MAX = 0x10FFFF,
U8_1BYTE_MAX = 0x7F,
U8_2BYTE_MIN = 0x80,
U8_2BYTE_MAX = 0x7FF,
U8_3BYTE_MIN = 0x800,
U8_3BYTE_MAX = 0xFFFF,
U8_4BYTE_MIN = 0x10000,
U8_4BYTE_MAX = UNICODE_MAX,
U16_1WORD_MAX = 0xFFFF,
U16_2WORD_MIN = 0x10000,
U16_2WORD_MAX = UNICODE_MAX,
};
void str::putCpNe (char*& p, unsigned long aCp)
{
if (aCp <= U8_2BYTE_MAX) { // 1 or 2 bytes, the most frequent case
if (aCp <= U8_1BYTE_MAX) { // 1 byte
*(p++) = static_cast<char>(aCp);
} else { // 2 bytes
*(p++) = static_cast<char>((aCp >> 6) | 0xC0);
*(p++) = static_cast<char>((aCp & 0x3F) | 0x80);
}
} else { // 3 or 4 bytes
if (aCp <= U8_3BYTE_MAX) { // 3 bytes
*(p++) = static_cast<char>( (aCp >> 12) | 0xE0);
*(p++) = static_cast<char>(((aCp >> 6) & 0x3F) | 0x80);
*(p++) = static_cast<char>( (aCp & 0x3F) | 0x80);
} else { // 4 bytes
*(p++) = static_cast<char>(((aCp >> 18) & 0x07) | 0xF0);
*(p++) = static_cast<char>(((aCp >> 12) & 0x3F) | 0x80);
*(p++) = static_cast<char>(((aCp >> 6) & 0x3F) | 0x80);
*(p++) = static_cast<char>( (aCp & 0x3F) | 0x80);
}
}
}
void str::appendCp(std::string & s, unsigned long aCp)
{
char c[5];
char* end = c;
putCpNe(end, aCp);
s.append(c, end);
}Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question