Answer the question
In order to leave comments, you need to log in
How to solve the problem of determining the uniformity of the cluster load?
We launch several analytical calculations in different client environments on clusters of temporary cloud machines.
I would like to take a smart approach to the issue of resource utilization efficiency.
In distributed computing, it is very important that there is no situation when one machine does the work, and all the others are waiting for it.
The task can be presented formally:
Comparing the utilization schedules of a certain resource (for example, CPU) of each of the cluster machines, we can derive the load uniformity coefficient. If the recycling schedules for all machines are approximately the same, it can be assumed that such a cluster distributes the load more efficiently, compared to a situation where the recycling schedules coincide worse.
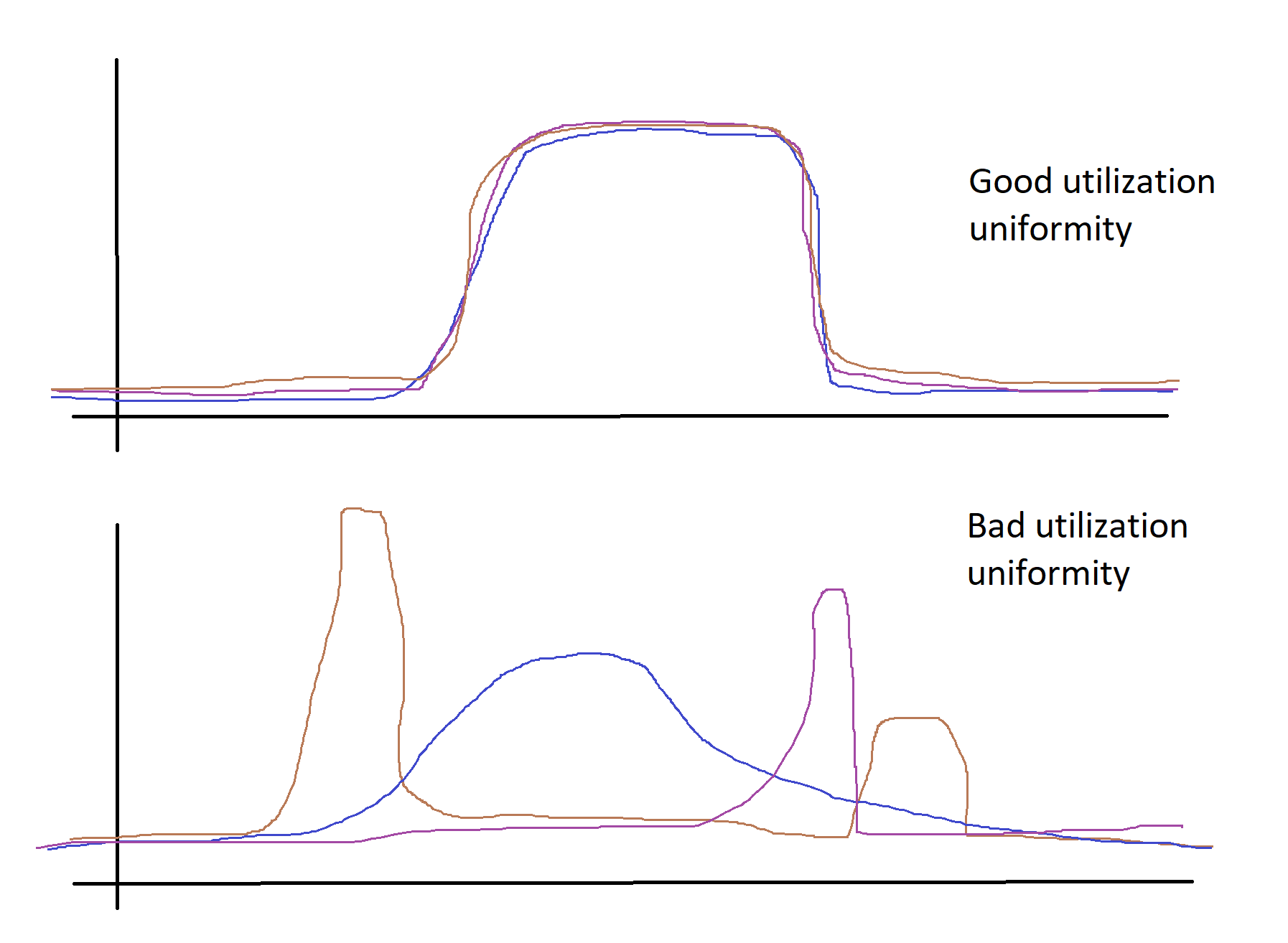
Having such an efficiency index for each run of the calculation, you can significantly improve the understanding of which calculation should be improved in the first place.
Before you start inventing such a library yourself, I would like to know if there are projects in nature that solve such a problem? The idea does not look like something extraordinary.
Answer the question
In order to leave comments, you need to log in
there are no projects - because programmers write algorithmically correct and programmatically literate code , right
?
and so - APM services, new relic and others like them
look at the cpu benchmark and just different benchmarks - there is not and cannot be something a priori evaluating the performance of software on a given hardware - practice always turns out to be different
Well, just do this is done by specialists who develop tasks for Spark.
In theory, after the development and launch of the task, such a specialist can go to the UI and see the distribution of resources, for example, by estimating the time of work for different tasks.
There are other approaches, but in any case, the one who develops the task for the spark should do this, because it’s just to know that your resources are not evenly distributed, it’s pointless without such a person, and this person already has tools for assessing the uniformity of resource distribution.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question