Answer the question
In order to leave comments, you need to log in
How to skip or read all?
The essence of the question is that you need to parse data from the site, but the object, for the parse, is laid under a strange, for me newbie, site structure. Actually structure The 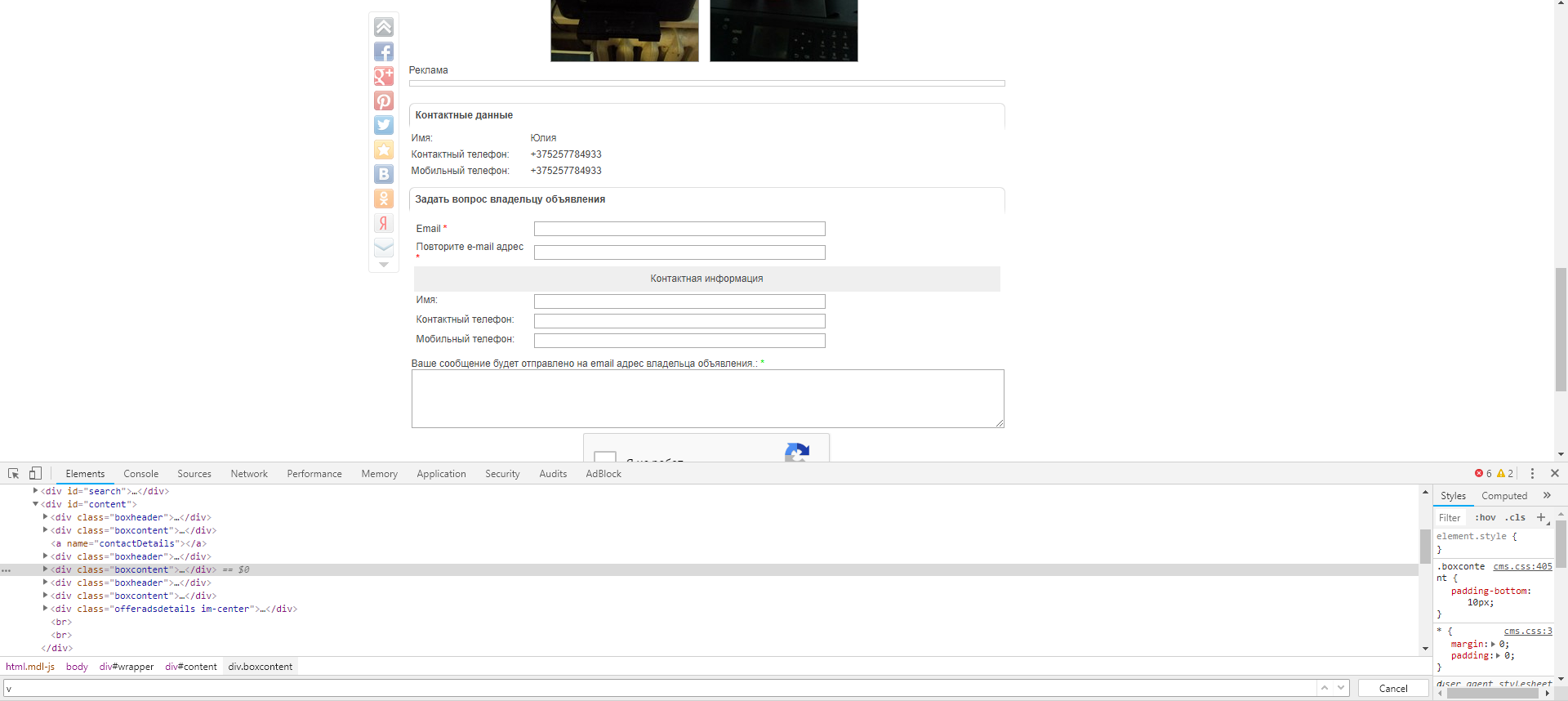
information necessary to me is in the second and my code reads only the first. When replacing the .find method with .findAll, the text becomes a list, which removes the ability to extract the values I need from it.
Question: how to skip, or read all?
mport urllib.request
from bs4 import BeautifulSoup
def get_html(url):
response = urllib.request.urlopen(url)
return response.read()
def parse(html):
soup = BeautifulSoup(html, "html.parser")
div = soup.find("div", id="wrapper")
diver = div.find("div", id="content")
content = diver.find("div", class_="boxcontent")
print(content)
def main():
parse(get_html('http://mogilev.ekomissionka.by/ru-i-offer-i-id-i-732729-i-mfu-canon-maxify-mb2040-canon.html'))
if __name__ == '__main__':
main()<div class="boxcontent">
<div class="offerdetail">
<h1>
Мфу Canon maxify mb2040 - Многофункциональные устройства
</h1>
<a href="http://mogilev.ekomissionka.by/ru-i-classifieds-i-category-i-mnogofunktsionalinye-ustrojstva-i-p.html">
Продам, предлагаю - частное лицо: Многофункциональные устройства
</a>
,
<a href="http://mogilev.ekomissionka.by/ru-i-classifieds-i-category-i-mnogofunktsionalinye-ustrojstva-i-p.html">
Беларусь, Могилев
</a>
<div align="right" class="buttons">
<a href="javascript://" onclick="javascript:history.back(1)" rel="nofollow">
<img alt="Назад к списку" border="0" height="26" src="http://mogilev.ekomissionka.by/templates/front/layouts/default/images/icons/back.gif" title="Назад к списку" width="30"/>
</a>
<a href="javascript://" onclick="popup('http://mogilev.ekomissionka.by/ru-i-offer-i-id-i-732729-i-windowMode-i-print-i-p.html')" rel="nofollow">
<img alt="Распечатать" border="0" height="26" src="http://mogilev.ekomissionka.by/templates/front/layouts/default/images/icons/print.gif" title="Распечатать" width="30"/>
</a>
</div>
<div class="source">
<b>
Код: 732729
</b>
Создано: 15-05-2018 08:09
</div>
<h3>
Цена: 80 руб. Br
</h3>
<!-- AddThis Button BEGIN -->
<!-- AddThis Button END -->
<table cellpadding="0" cellspacing="0" width="100%">
<tr>
<td class="detailedcontent" valign="top" width="50%">
<p>
Мфу Canon maxify mb2040. Состояние отличное. Работает замечательно. Имеется комплект перезаправляемых картриджей полностью заполненных краской. Картриджи требуют обнуление и будут служить ещё долго. В бутылочках есть цветные краски, которых хватит на ещё один раз. Звоните пока краска не засохла
</p>
<ul>
<li>
<a class="warning" href="javascript://" onclick="ahah('http://mogilev.ekomissionka.by/ru-i-ahah-i-boxid-i-mail.contactFormahah-i-requestedSID-i-offer','ComplainForResourceOffer');">
Пожаловаться на объявление
</a>
</li>
</ul>
<div id="ComplainForResourceOffer">
</div>
</td>
<td align="right" class="detailedcontent" valign="top" width="50%">
<br/>
<div class="adcode">
<script type="text/javascript">
<!--
google_ad_client = "ca-pub-1815756144625787";
/* Ekomissionka.by - image2 */
google_ad_slot = "8450970029";
google_ad_width = 300;
google_ad_height = 250;
//-->
</script>
<script src="http://pagead2.googlesyndication.com/pagead/show_ads.js" type="text/javascript">
</script>
</div>
</td>
</tr>
</table>
</div>
<div class="boxheader">
<h3>
Картинки
</h3>
</div>
<div class="boxcontent">
<div align="center">
<!-- <a href="javascript://" class="image" onClick="popup('http://mogilev.ekomissionka.by/ru-i-originalimage-i-path-i-2018-f-20180515-f-visitor-f-images-f-201805-f-f20180515080605-img_20180512_132418_hdr.jpg',820,1087)"><img src="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/p20180515080605-img_20180512_132418_hdr.jpg" border="0" /></a> -->
<a class="image" href="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/f20180515080605-img_20180512_132418_hdr.jpg" rel="lightbox[plants]">
<img border="0" src="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/p20180515080605-img_20180512_132418_hdr.jpg"/>
</a>
</div>
<div align="center">
<!-- <a href="http://mogilev.ekomissionka.by/templates/front/js/images/image-1.jpg" rel="lightbox"><img src="http://mogilev.ekomissionka.by/templates/front/js/images/thumb-1.jpg" alt="" height="40" width="100"></a> -->
<table>
<tr>
<td align="left" valign="top">
<a class="image" href="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/f20180515080702-img_20180507_201623_hdr.jpg" rel="lightbox[plants]">
<img border="0" src="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/i20180515080702-img_20180507_201623_hdr.jpg"/>
</a>
</td>
<td align="left" valign="top">
<a class="image" href="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/f20180515080715-img_20180507_201638_hdr.jpg" rel="lightbox[plants]">
<img border="0" src="http://mogilev.ekomissionka.by/content/2018/20180515/visitor/images/201805/i20180515080715-img_20180507_201638_hdr.jpg"/>
</a>
</td>
</tr>
</table>
</div>
Реклама
<div class="offeradsdetails im-center">
<div class="adcode">
<script type="text/javascript">
<!--
google_ad_client = "pub-1815756144625787";
/* 336x280, создано 02.03.10 */
google_ad_slot = "6817292703";
google_ad_width = 336;
google_ad_height = 280;
//-->
</script>
<script src="http://pagead2.googlesyndication.com/pagead/show_ads.js" type="text/javascript">
</script>
</div>
</div>
</div>
</div>Answer the question
In order to leave comments, you need to log in
In continuation to my comment, I will add that, apparently, "The information I need is" not in the second, but in the third (the first boxcontent contains one more inside itself) - if this is the case, I can suggest adding 4 more lines to your code before this result:
def parse(html):
soup = BeautifulSoup(html, "html.parser")
div = soup.find("div", id="wrapper")
diver = div.find("div", id="content")
content = diver.findAll("div", class_="boxcontent")
data_lst = content[2].findAll("tr")
for field in data_lst:
f = field.findAll("td")
print('%s\t%s\t%s' % tuple(map(lambda t: t.text.strip(), f)))
##Имя: Юлия
##Контактный телефон: +375257784933
##Мобильный телефон: +375257784933Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question