Answer the question
In order to leave comments, you need to log in
How to properly use pandas indexes?
Hello, I am trying to solve this problem. She's interesting enough.
The function should take pandas.DataFrame as input, as in the image, and return the winner of the election as output.
The task also states that it is worth using the functions .idxmax(), .sort_index(), .groupby()
But
I have been unable to solve it for several hours...
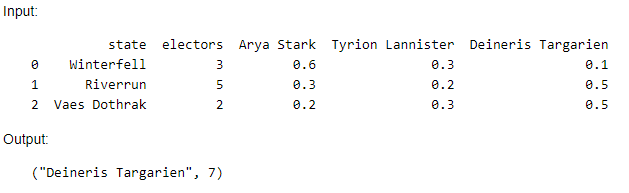
the value from the electors column
As far as I understand, I need to:
1. group by state
2. sort by candidate name
3. find the winner in each state
4. Then I somehow need to get the number of electors multiplied by "whether this candidate won", by all-or-nothing logic
Here is what my code looks like now:
def winner_votes(df_in):
df = df_in.groupby(['state', 'electors'], sort=False).first()
df.sort_index(axis=1, inplace=True)
df['winner'] = df.idxmax(axis=1)
return df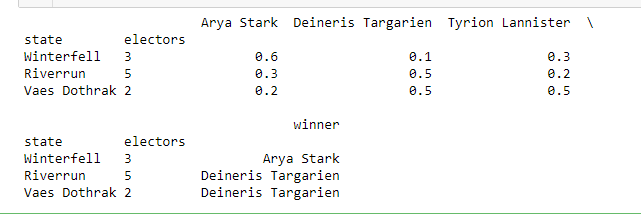
Answer the question
In order to leave comments, you need to log in
I found the solution with the involvement of more experienced colleagues :)
def winner_votes(df):
votes = df.drop(columns=['state']).set_index('electors')
votes = votes.T.sort_index().idxmax().reset_index()
votes = votes.groupby(0)['electors'].sum().nlargest(1)
return (list(votes.index)[0], list(votes.values)[0])I did not understand anything from the question, but the "winner" in the last given table is easy to find - we group by "winner" and calculate the sum of "electors" in the group. Then we choose the group (that candidate) who has the maximum amount.
If this is not an answer to your question - clarify, reformulate and ask a specific question so that you can understand what exactly you do not understand.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question