Answer the question
In order to leave comments, you need to log in
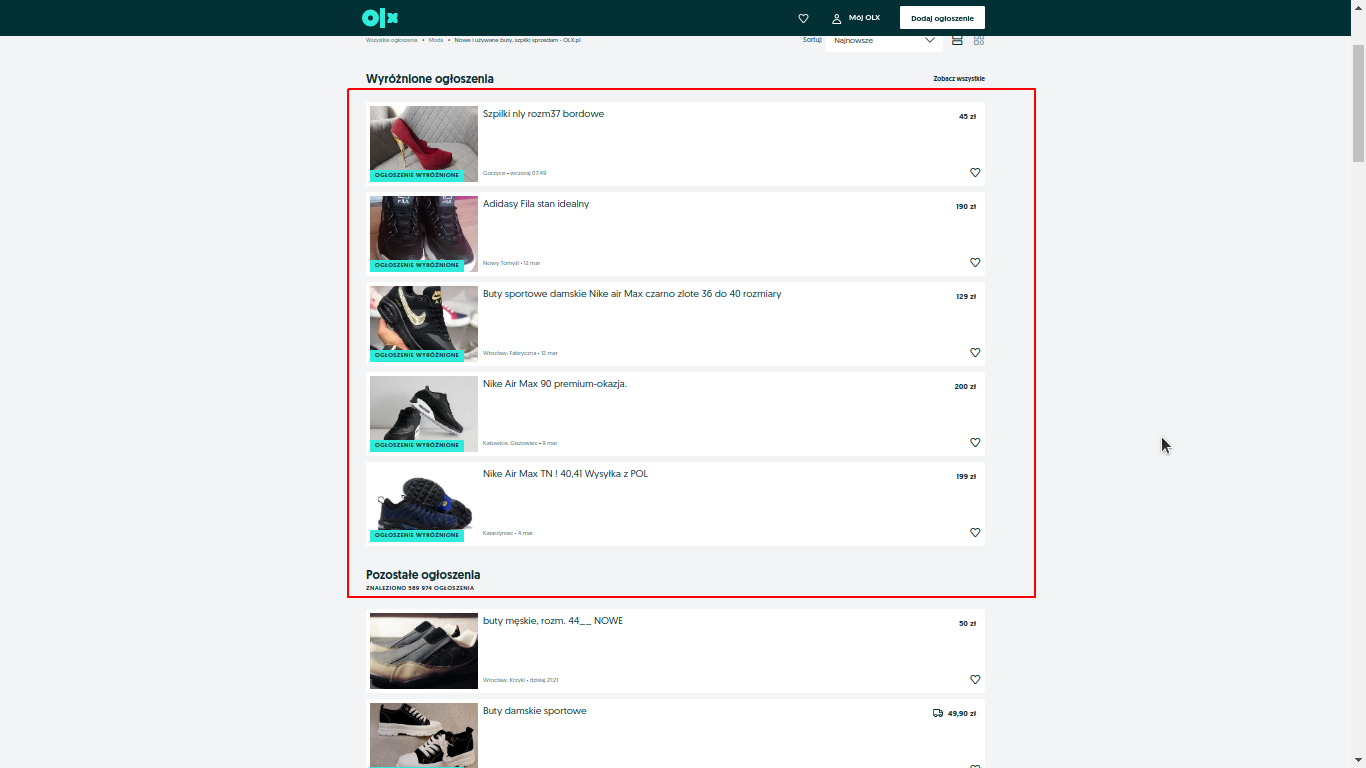
How to parse the site olx, error?
import requests
from bs4 import BeautifulSoup
def parse():
URL = 'https://www.olx.pl/moda/buty/?view=list'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
response = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(response.content, 'html.parser')
items = soup.findAll('div', class_='offer-wrapper')
ads = []
for item in items:
ads.append({
'title': item.find('a', class_='marginright5 link linkWithHash detailsLink').get_text(strip=True),
'link': item.find('a', class_='marginright5 link linkWithHash detailsLink').get('href'),
})
print(ads)
parse()'title': item.find('a', class_='marginright5 link linkWithHash detailsLink').get_text(strip=True),
AttributeError: 'NoneType' object has no attribute 'get_text'Answer the question
In order to leave comments, you need to log in
Start parsing from the 6th declaration, since the first 5 declarations have different classes:
for item in items[5:]:
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question