Answer the question
In order to leave comments, you need to log in
How to parse site date?
Greetings to all. I parse the date of the news from this portal . And after these received dates I convert to the format I need using the dateparser library . And such a dilemma occurred. This portal has two types of dates. That is, like this: 1 date type 2 date type
And now the 1st type has such a date 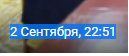
And the 2nd type has such a date 
2nd type of dates is parsed without problems. But type 1 displays None because I use the dateparser
library
Here is the format to which I convert using the dateparser library
2019-09-03 13:54:23
# < Собираем даты с страницы.
def get_item_datetime(item_page,datetime_rule,datetime1_rule):
if item_page is None:
return
soup = BeautifulSoup(item_page, 'lxml')
item_datetime = soup.find(datetime_rule[0],{datetime_rule[1]:datetime_rule[2]})
if item_datetime is not None:
item_datetime = soup.find(datetime_rule[0],{datetime_rule[1]:datetime_rule[2]}).text
item_datetime = dateparser.parse(item_datetime, date_formats=['%d %B %Y %H'])
else:
if (len(datetime1_rule) == 3):
item_datetime = soup.find(datetime1_rule[0],{datetime1_rule[1]:datetime1_rule[2]}).text
item_datetime = dateparser.parse(item_datetime, date_formats=['%d %B %Y %H'])
else:
item_datetime = ''
return item_datetime2019-09-03 13:54:23
Answer the question
In order to leave comments, you need to log in
Both pages have the format meta tag
Take it parse withdateutil
import requests
from lxml.html import fromstring
from dateutil import parser as dtparser
r = requests.get(url, headers=header)
html = fromstring(r.text)
dt_string = html.find('.//meta[@name="mediator_published_time"]').get('content')
dt_obj = dtparser.parse(dt_string)>>> datetime.datetime(2019, 9, 2, 22, 51, tzinfo=tzoffset(None, 21600))How about adding a year? And what will the date look like for last year then?
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question