Answer the question
In order to leave comments, you need to log in
How to parse data from a PDF table?
There is a class schedule for groups, which is sent every day in a pdf file in the form of a table.
You need to use python to extract the classes and classrooms of a specific group. I can't figure out how to implement it.
The file looks like this: 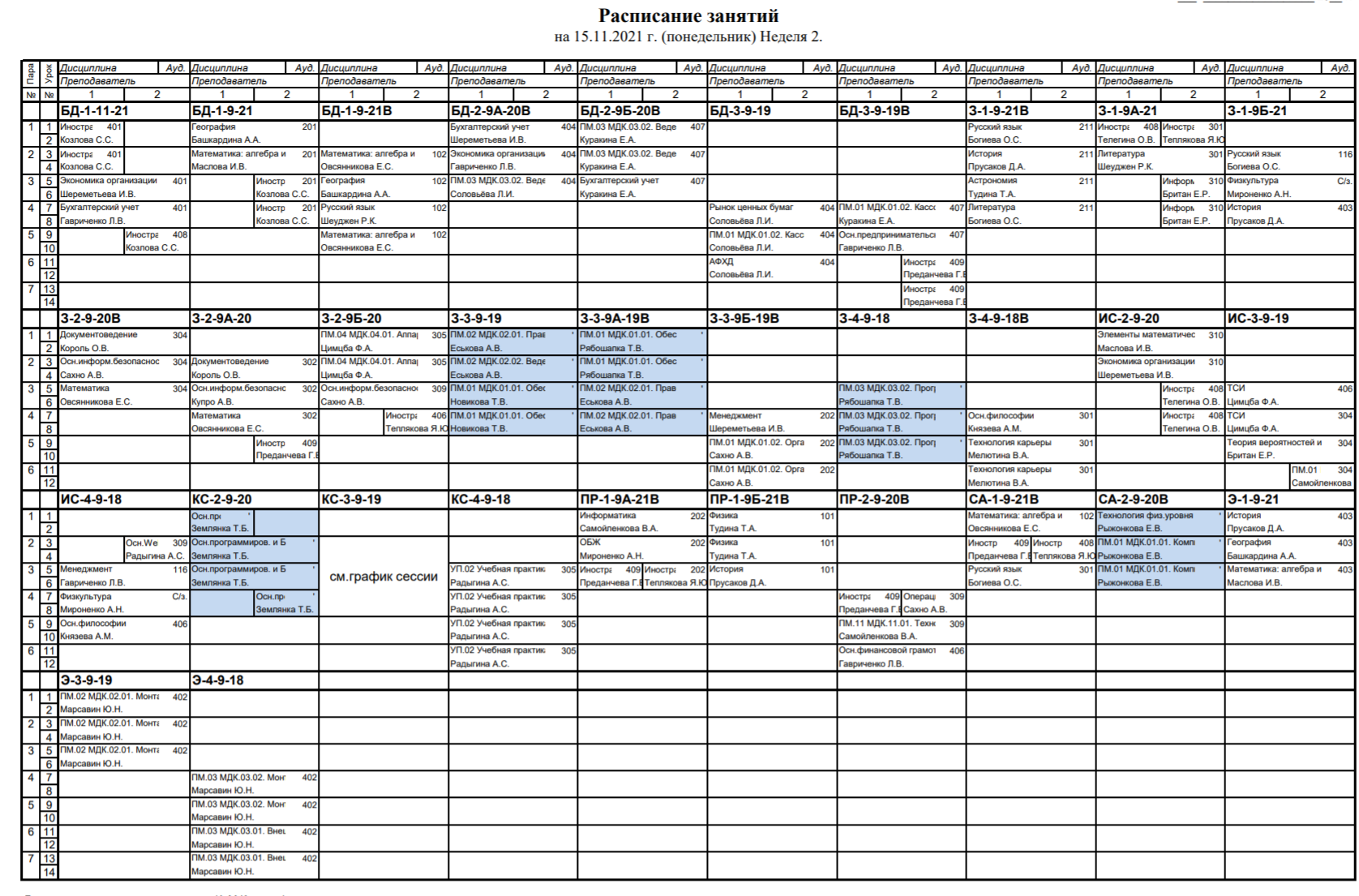
The result can be in the form of text, or in the form of a cropped photo with the activities of a certain group.
Tried different libraries like: tabula, PyPDF2, camelot. All I got was this:
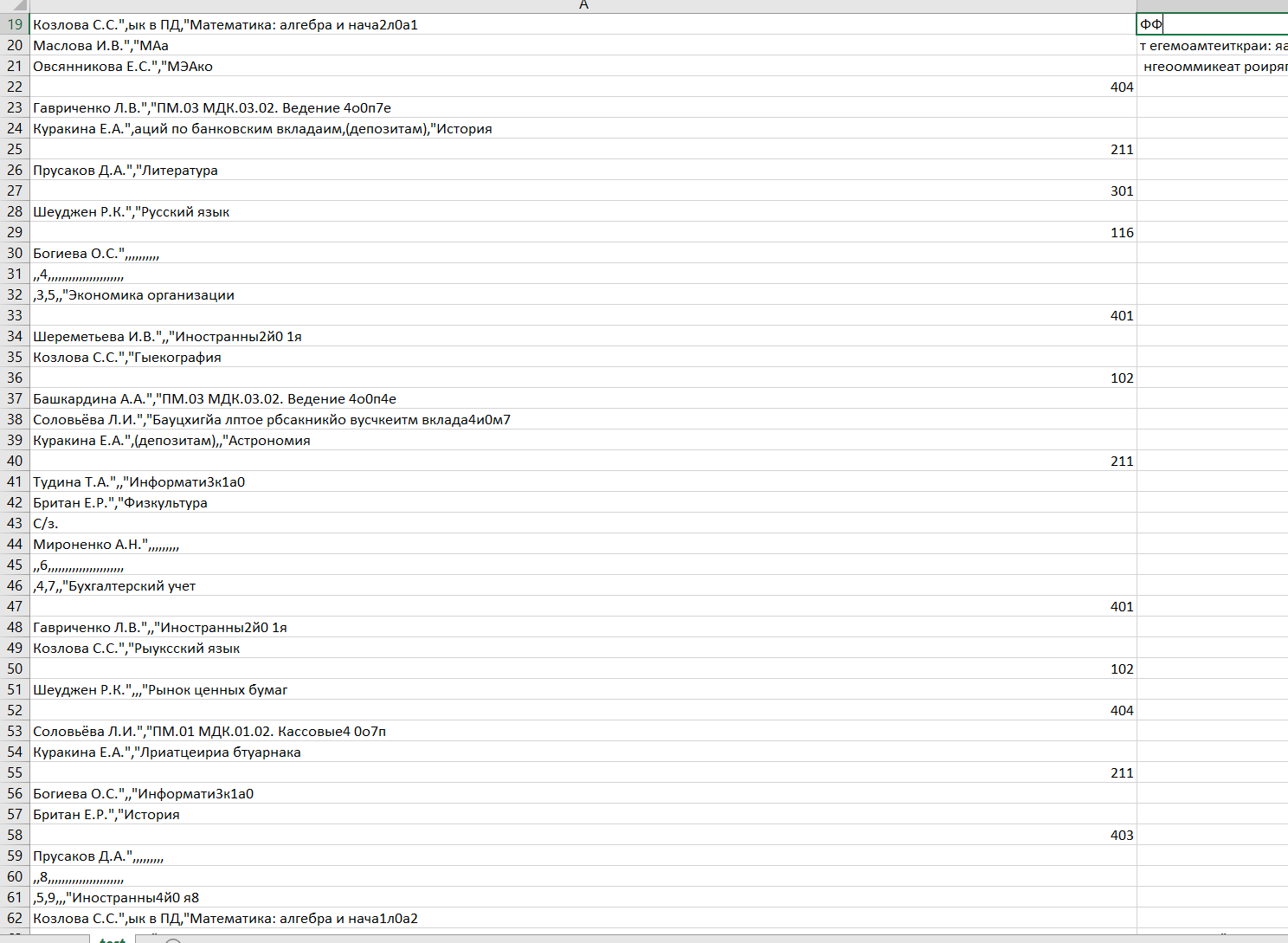
Also this option:
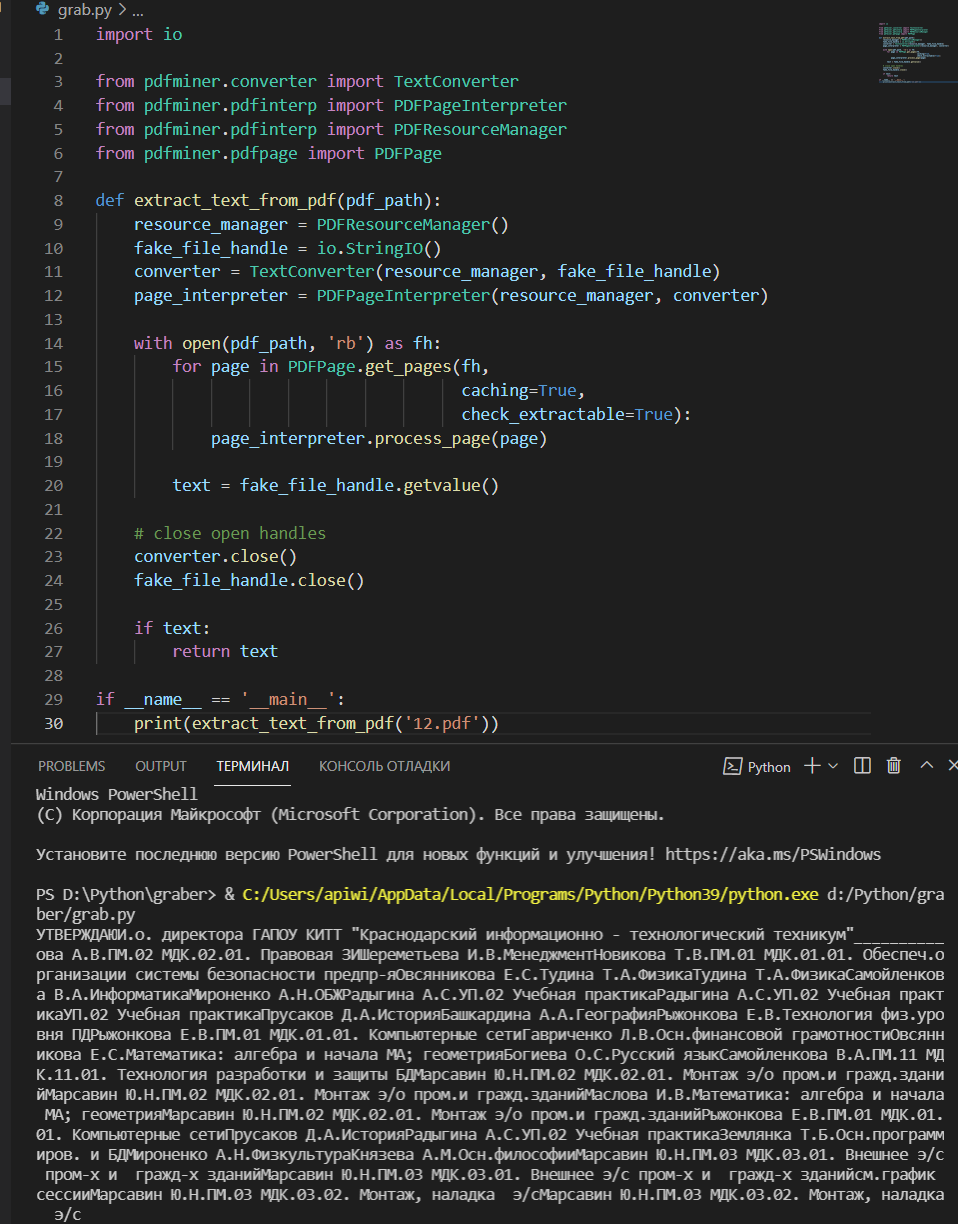
I understand that maybe you tell me to go to the freelance exchange, but no, I need to be pushed to the idea of completing the task. Thank you.
Answer the question
In order to leave comments, you need to log in
Solved the issue with: pdfminer, pdf2image, PIL
Found the coordinates of the desired text using pdfminer, converted it to an image using pdf2image and using PIL cropped the desired area (added values to the coordinates)
which is sent every day in a pdf file in the form of a table
Alas, it will not work out normally. (I regularly answer this question here)
For - pdf knows absolutely nothing about tables, it is a preprint language, there is nothing at all except text, fonts, blocks and graphic primitives! Accordingly, the data in it is absolutely not structured.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question