Answer the question
In order to leave comments, you need to log in
How to parse a table from html using Scrapy?
There is an html page with nested tables 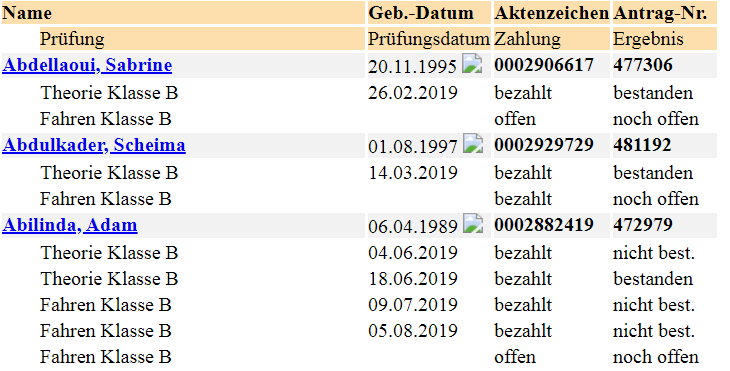
. The html table of interest looks like this:
<tr valign="top">
<td colspan="2" bgcolor="F2F2F2"><a href="/trk/fe/TEDIS_466.nsf/,DanaInfo=extranet2.de.tuv.com+Antragsdaten?OpenAgent&U=9FE850F57F956872C1258366002703BB"><b>Abdellaoui, Sabrine</b></a></td>
<td bgcolor="F2F2F2">20.11.1995 <img src="/trk/fe/TEDIS_466.nsf/,DanaInfo=extranet2.de.tuv.com+empty.gif?OpenImageResource" border="0" align="BOTTOM"></td>
<td bgcolor="F2F2F2"><b>0002906617</b></td>
<td bgcolor="F2F2F2"><b>477306</b></td>
</tr>
<tr valign="MIDDLE">
<td> </td>
<td bgcolor="FFFFFF">Theorie Klasse B</td>
<td bgcolor="FFFFFF">26.02.2019</td>
<td bgcolor="FFFFFF">bezahlt</td>
<td bgcolor="FFFFFF">bestanden</td>
</tr>
<tr valign="MIDDLE">
<td> </td>
<td bgcolor="FFFFFF">Fahren Klasse B</td>
<td bgcolor="FFFFFF"></td>
<td bgcolor="FFFFFF">offen</td>
<td bgcolor="FFFFFF">noch offen</td>
</tr>
<tr valign="top">
<td colspan="2" bgcolor="F2F2F2"><a href="/trk/fe/TEDIS_466.nsf/,DanaInfo=extranet2.de.tuv.com+Antragsdaten?OpenAgent&U=513F853FA943F430C1258397002C01AF"><b>Abdulkader, Scheima</b></a></td>
<td bgcolor="F2F2F2">01.08.1997 <img src="/trk/fe/TEDIS_466.nsf/,DanaInfo=extranet2.de.tuv.com+empty.gif?OpenImageResource" border="0" align="BOTTOM"></td>
<td bgcolor="F2F2F2"><b>0002929729</b></td>
<td bgcolor="F2F2F2"><b>481192</b></td>
</tr>
<tr valign="MIDDLE">
<td> </td>
<td bgcolor="FFFFFF">Theorie Klasse B</td>
<td bgcolor="FFFFFF">14.03.2019</td>
<td bgcolor="FFFFFF">bezahlt</td>
<td bgcolor="FFFFFF">bestanden</td>
</tr>
<tr valign="MIDDLE">
<td> </td>
<td bgcolor="FFFFFF">Fahren Klasse B</td>
<td bgcolor="FFFFFF"></td>
<td bgcolor="FFFFFF">bezahlt</td>
<td bgcolor="FFFFFF">noch offen</td>
</tr>def parse(self, response):
all = response.xpath('//table[position()>2]/tbody')
for fld in all:
Item = DataItem()
names = fld.xpath('//tr/td/a/b/text()').extract()
bday = fld.xpath('//tr[@valign="top"]/td[position()=2]/text()').getall()
pass_number = fld.xpath('//tr/td[position()=3]/b/text()').getall()
order_number = fld.xpath('//tr/td[position()=4]/b/text()').getall()
exam_name = fld.xpath('//tr[@valign="MIDDLE"]/td[position()=2]/text()').getall()
exam_date = fld.xpath('//tr[@valign="MIDDLE"]/td[position()=3]/text()').getall()
exam_pay = fld.xpath('//tr[@valign="MIDDLE"]/td[position()=4]/text()').getall()
exam_result =fld.xpath('//tr[@valign="MIDDLE"]/td[position()=5]/text()').getall()
Item['name'] = names[1]
Item['gebDatum'] = bday[1][0:10]
Item['aktenzeichen'] = pass_number[1]
Item['antragNr'] = order_number[1]
Item['prufung'] = exam_name[0:2]
Item['prufungsdatum'] = exam_date[0:2]
Item['Zahlung'] = exam_pay[0:2]
Item['Ergebnis'] = exam_result[0:2]
yield ItemAnswer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question