Answer the question
In order to leave comments, you need to log in
How to parse a site through an rss feed into a file?
Good night,
knowledgeable people, tell me how to use simple_html_dom.php with
www.hltv.org/hltv.rss.php
to parse
links from this feed, namely:
1-names of teams playing each other
2-team logos
3-match start time
4-name of the tournament
5-list of maps (most often known 5-30 minutes before the start of the game)
6-game format (best of 1, best of 2, etc.)
7-match score if the game is over
8-commands of teams
9- player photos
10-player flags 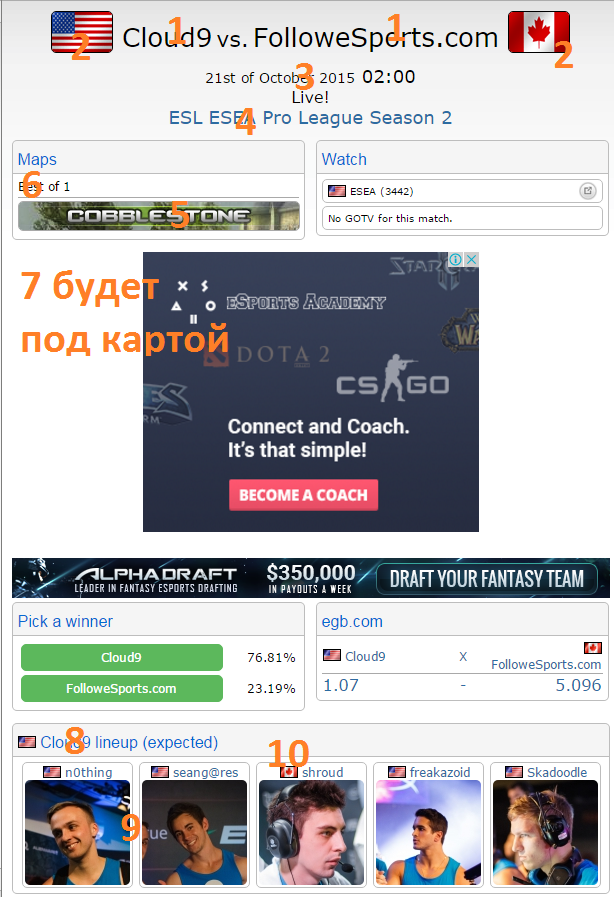
Parse everything into some file like xml or the like.
drew attention to the question here
Can't parse correctly with PHP Simple Dom Parser?
and maybe on the parser herehttps://github.com/KenanY/hltv-match/blob/master/i...
Answer the question
In order to leave comments, you need to log in
Use the https://github.com/olamedia/nokogiri library , everything will be easier with it.
Rss contains only the following data: title (title, 2 teams), link (link), description (tournament), pubDate (date). Therefore, only them can be pulled out from there.
$html = file_get_html('www.hltv.org/hltv.rss.php');
foreach($html->find('item') as $element)
$title = $element->find('title', 0)->plaintext;
$link = $element->find('link', 0)->plaintext;
$description = $element->find('description' , 0)->plaintext;
$pubDate = $element->find('pubDate', 0)->plaintext;
}I recommend using XSLT for parsing html - it's the fastest way in terms of performance. Templates, of course, are cumbersome, but these are trifles, and slow heavy third-party libraries are not needed.
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question