Answer the question
In order to leave comments, you need to log in
How to parse a link if there is data-ipb="noparse"?
import requests
from bs4 import BeautifulSoup as bs
headers = {'accept': '*/*',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 4.0.2; en-us; Galaxy Nexus Build/ICL53F) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'}
base_url = 'https://www.biznet.ru/topic305118.html/page-2#entry2183295'
def bf_parse(base_url, headers):
session = requests.session()
request = session.get(base_url, headers=headers)
if request.status_code == 200:
soup = bs(request.content, 'html.parser')
div = soup.find_all('div', attrs={'class': "topic_reply"})
print(div)
bf_parse(base_url, headers)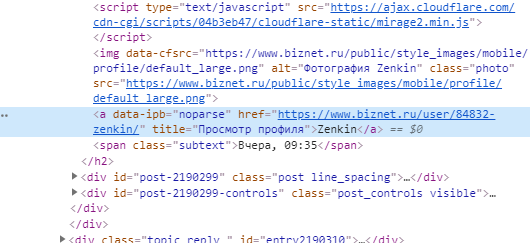
Answer the question
In order to leave comments, you need to log in
Didn't find what you were looking for?
Ask your questionAsk a Question
731 491 924 answers to any question